Software is anything but simple. Even seemingly basic applications might have a rat’s nest of dependencies, with scores of packages, libraries, and other software components required for them to run. When you try to run multiple applications in the same operating system environment, you might well find that some of these components don’t get along. And when you try to keep those software stacks up-to-date, or change them to keep up with business needs, you bring in all kinds of maintenance headaches.
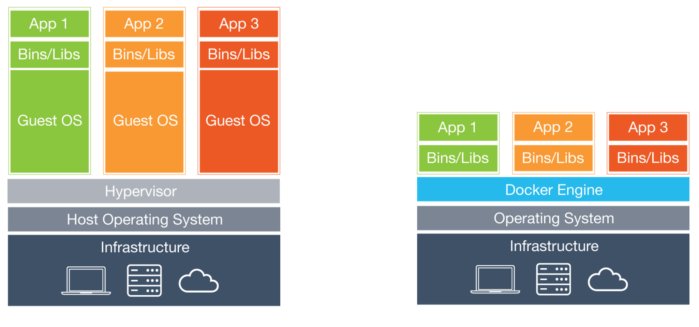
For many years now, the leading way to isolate and organize applications and their dependencies has been to place each application in its own virtual machine. Virtual machines make it possible to run multiple applications on the same physical hardware while keeping conflicts among software components and competition for hardware resources to a minimum. But virtual machines are bulky—typically gigabytes in size. They don’t really solve problems like portability, software updates, or continuous integration and continuous delivery.
Enter Docker containers. Containers make it possible to isolate applications into small, lightweight execution environments that share the operating system kernel. Typically measured in megabytes, containers use far fewer resources than virtual machines and start up almost immediately. They can be packed far more densely on the same hardware and spun up and down en masse with far less effort and overhead.
Thus containers provide a highly efficient and highly granular mechanism for combining software components into the kinds of application and service stacks needed in a modern enterprise, and for keeping those software components updated and maintained.
Docker container basics
Docker containers are the most modern incarnation of an idea that has been in Unix operating systems such as BSD and Solaris for decades—the idea that a given process can be run with some degree of isolation from the rest of the operating environment.
Virtual machines provide isolation by devoting an entire operating system instance to each application that needs compartmentalizing. This approach provides almost total isolation, but at the cost of significant overhead. Each guest operating instance eats up memory and processing power that could be better devoted to apps themselves.
Containers take a different approach. Each application and its dependencies use a partitioned segment of the operating system’s resources. The container runtime (Docker, most often) sets up and tears down the containers by drawing on the low-level container services provided by the host operating system.
To understand Linux containers, for example, we have to start with cgroups and namespaces, the Linux kernel features that create the walls between containers and other processes running on the host. Linux namespaces, originally developed by IBM, wrap a set of system resources and present them to a process to make it look like they are dedicated to that process.
Linux cgroups, originally developed by Google, govern the isolation and usage of system resources, such as CPU and memory, for a group of processes. For example, if you have an application that takes up a lot of CPU cycles and memory, such as a scientific computing application, you can put the application in a cgroup to limit its CPU and memory usage.
Namespaces deal with resource isolation for a single process, while cgroups manage resources for a group of processes. Together, cgroups and namespaces were used to create a container technology called, appropriately enough, Linux Containers, or LXC.
Docker
How the virtualization and container infrastructure stacks stack up.
How Docker changed containers
The original Linux container technology, LXC is a Linux operating system level virtualization method for running multiple isolated Linux systems on a single host. Namespaces and cgroups make LXC possible.
Containers decouple applications from operating systems, which means that users can have a clean and minimal Linux operating system and run everything else in one or more isolated container.
Also, because the operating system is abstracted away from containers, you can move a container across any Linux server that supports the container runtime environment.
Docker introduced several significant changes to LXC that make containers more portable and flexible to use. Using Docker containers, you can deploy, replicate, move, and back up a workload even more quickly and easily than you can do so using virtual machines. Docker brings cloudlike flexibility to any infrastructure capable of running containers.
Docker also provides a way to create container images—specifications for which software components a given container would run and how. Docker’s container image tools allow a developer to build libraries of images, compose images together into new images, and launch the apps in them on local or remote infrastructure.
Docker also makes it easier to coordinate behaviors between containers, and thus build application stacks by hitching containers together. More advanced versions of these behaviors—what’s called container orchestration—are offered by third-party products, such as Kubernetes. But Docker provides the basics.
By taking the LXC concept and building an API and ecosystem around it, the developers of Docker have made working with containers far more accessible to developers and far more useful to enterprises.
Finally, although Docker was originally built atop LXC, eventually the Docker team created its own runtime, called libcontainer. Libcontainer not only provides a richer layer of services for containers, but also makes it easier for the Docker team to develop Docker container technology separately from Linux.
Today, Docker is a Linux or Windows utility that can efficiently create, ship, and run containers.
Docker advantages
Docker containers provide a way to build enterprise and line-of-business applications that are easier to assemble, maintain, and move around than their conventional counterparts.
Docker containers enable isolation and throttling
Docker containers keep apps isolated not only from each other, but from the underlying system. This not only makes for a cleaner software stack, but makes it easier to dictate how a given containerized application uses system resources—CPU, GPU, memory, I/O, networking, and so on. It also makes it easier to ensure that data and code are kept separate. (See “Docker containers are stateless and immutable,” below.)
Docker containers enable portability
A Docker container runs on any machine that supports the container’s runtime environment. Applications don’t have to be tied to the host operating system, so both the application environment and the underlying operating environment can be kept clean and minimal.
For instance, a MySQL for Linux container will run on most any Linux system that supports containers. All of the dependencies for the app are typically delivered in the same container.
Container-based apps can be moved easily from on-prem systems to cloud environments or from developers’ laptops to servers, as long as the target system supports Docker and any of the third-party tools that might be in use with it, such as Kubernetes (see “Docker containers ease orchestration and scaling”, below).
Normally, Docker container images must be built for a specific platform. A Windows container, for instance, will not run on Linux and vice versa. Previously, one way around this limitation was to launch a virtual machine that ran an instance of the needed operating system, and run the container in the virtual machine.
However, the Docker team has since devised a more elegant solution, called manifests, which allow images for multiple operating systems to be packed side-by-side in the same image. Manifests are still considered experimental, but they hint at how containers might become a cross-platform application solution as well as a cross-environment one.
Docker containers enable composability
Most business applications consist of several separate components organized into a stack—a web server, a database, an in-memory cache. Containers make it possible to compose these pieces into a functional unit with easily changeable parts. Each piece is provided by a different container and can be maintained, updated, swapped out, and modified independently of the others.
This is essentially the microservices model of application design. By dividing application functionality into separate, self-contained services, the microservices model offers an antidote to slow traditional development processes and inflexible monolithic apps. Lightweight and portable containers make it easier to build and maintain microservices-based applications.
Docker containers ease orchestration and scaling
Because containers are lightweight and impose little overhead, it’s possible to launch many more of them on a given system. But containers can also be used to scale an application across clusters of systems, and to ramp services up or down to meet spikes in demand or to conserve resources.
The most enterprise-grade versions of the tools for deployment, managing, and scaling containers are provided by way of third-party projects. Chief among them is Google’s Kubernetes, a system for automating how containers are deployed and scaled, but also how they’re connected together, load-balanced, and managed. Kubernetes also provides ways to create and re-use multi-container application definitions or “Helm charts,” so that complex app stacks can be built and managed on demand.
Docker also includes its own built-in orchestration system, swarm mode, which is still used for cases that are less demanding. That said, Kubernetes has become something of the default choice; in fact, Kubernetes is bundled with Docker Enterprise Edition.
Docker caveats
Containers solve a great many problems, but they aren’t cure-alls. Some of their shortcomings are by design; some are by-products of their nature.
Docker containers are not virtual machines
The most common conceptual mistake people make with containers is to equate them with virtual machines. However, because containers and virtual machines use different isolation mechanisms, they have distinctly different advantages and disadvantages.
Virtual machines provide a high degree of isolation for processes, since they run in their own instance of an operating system. That operating system doesn’t have to be the same as the one run on the host, either. A Windows virtual machine can run on a Linux hypervisor and vice versa.
Containers, by contrast, use controlled portions of the host operating system’s resources; many applications share the same OS kernel, in a highly managed way. As a result, containerized apps aren’t as thoroughly isolated as virtual machines, but they provide enough isolation for the vast majority of workloads.
Microsoft offers two types of containers on Windows that blur the lines slightly between containers and virtual machines:
- Windows Server Containers are essentially Docker-style containers on Windows. Microsoft essentially provided the Windows kernel with some of the same mechanisms used in Linux to perform the isolation, so Docker containers could have the same behaviors on both platforms.
- Hyper-V Containers are containers that run in their own virtual machine with their own kernel for additional isolation. Thus Hyper-V Containers can run different versions of the Windows kernel if needed. Conventional containers can be converted to Hyper-V Containers if the need arises.
Keep in mind that, while Hyper-V Containers run on the Hyper-V hypervisor and take advantage of Hyper-V isolation, they are still a different animal than full-blown virtual machines.
Docker containers don’t provide bare-metal speed
Containers don’t have nearly the overhead of virtual machines, but their performance impact is still measureable. If you have a workload that requires bare-metal speed, a container might be able to get you close enough—much closer than a VM—but you’re still going to see some overhead.
Docker containers are stateless and immutable
Containers boot and run from an image that describes their contents. That image is immutable by default—once created, it doesn’t change.
Consequently, containers don’t have persistency. If you start a container instance, then kill it and restart it, the new container instance won’t have any of the stateful information associated with the old one.
This is another way containers differ from virtual machines. A virtual machine has persistency across sessions by default, because it has its own file system. With a container, the only thing that persists is the image used to boot the software that runs in the container; the only way to change that is to create a new, revised container image.
On the plus side, the statelessness of containers makes the contents of containers more consistent, and easier to compose predictably into application stacks. It also forces developers to keep application data separate from application code.
If you want a container to have any kind of persistent state, you need to place that state somewhere else. That could be a database or a stand-alone data volume connected to the container at boot time.
Docker containers are not microservices
I mentioned earlier how containers lend themselves to creating microservices applications. That doesn’t mean taking a given application and sticking it into a container will automatically create a microservice. A microservices application must be built according to a microservice design pattern, whether it is deployed in containers or not. It is possible to containerize an application as part of the process of converting it to a microservice, but that’s only one step among many.
When virtual machines came along, they made it possible to decouple applications from the systems they ran on. Docker containers take that idea several steps further—not just by being more lightweight, more portable, and faster to spin up than virtual machines, but also by offering scaling, composition, and management features that virtual machines can’t.
