
Time series data is one of the fastest growing categories across a variety of industry segments, such as application monitoring, DevOps, clickstream analysis, network traffic monitoring, industrial IoT, consumer IoT, manufacturing, and many more. Customers want to track billions of time series monitoring hundreds of millions of devices, industrial equipment, gaming sessions, streaming video sessions, and more in a single system that can reliably and continuously ingest terabytes of data per day, answer fast queries on recent data, and efficiently analyze petabytes of recent and historical data. Many single-node or instance-based systems can’t handle this scale and tip over, resulting in an unresponsive or unavailable system.
To address this need, we purpose-built Amazon Timestream from the ground up to be a highly scalable and highly available time series database. Timestream is serverless, so you don’t need to provision resources upfront. The ingestion, storage, and query subsystems in Timestream automatically scale independently based on the load. This independent scaling enables a key scenario in time series use cases where you want high throughput data ingestion and concurrent queries run in parallel to ingestion that derive real-time insights. Timestream durably stores all data, seamlessly moves older data (based on user-specified configuration) into cost-optimized storage, and scales resources based on the volume of data a query accesses, allowing a single query to efficiently analyze terabytes of data. These scaling characteristics allow you to store and analyze time series data of any scale with Timestream. After you design your application using Timestream, as the application’s data and request volumes grow, Timestream automatically scales the resources. You only pay for what you use without needing to over-provision for peak, or redesign your application as your workload scales. For more information about the key benefits of Timestream and its use cases, see Timestream documentation.
In this post, we discuss the scale and performance characteristics of Timestream using an example application modeled on a DevOps use case. This example workload is derived from conversations with hundreds of customers with many different types of use cases, such as gaming, clickstream analysis, monitoring streaming applications, monitoring services, industrial telemetry, and IoT scenarios.
Overview of the workload
In this section, we discuss the ingestion and query workload corresponding to an application which is monitored using Timestream.
Application model
For this post, we use a sample application mimicking a DevOps scenario monitoring metrics from a large fleet of servers. Users want to alert on anomalous resource usage, create dashboards on aggregate fleet behavior and utilization, and perform sophisticated analysis on recent and historical data to find correlations. The following diagram provides an illustration of the setup where a set of monitored instances emit metrics to Timestream. Another set of concurrent users issues queries for alerts, dashboards, or ad-hoc analysis, where queries and ingestion run in parallel.
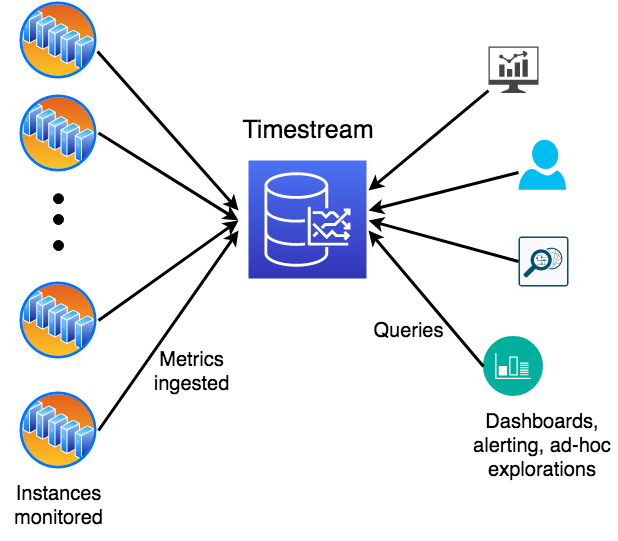
The application being monitored is modeled as a highly scaled-out service that is deployed in several regions across the globe. Each region is further subdivided into a number of scaling units called cells that have a level of isolation in terms of infrastructure within the region. Each cell is further subdivided into silos, which represent a level of software isolation. Each silo has five microservices that comprise one isolated instance of the service. Each microservice has several servers with different instance types and OS versions, which are deployed across three availability zones. These attributes that identify the servers emitting the metrics are modeled as dimensions in Timestream. In this architecture, we have a hierarchy of dimensions (such as region, cell, silo, and microservice_name) and other dimensions that cut across the hierarchy (such as instance_type and availability_zone).
The application emits a variety of metrics (such as cpu_user and memory_free) and events (such as task_completed and gc_reclaimed). Each metric or event is associated with eight dimensions (such as region or cell) that uniquely identify the server emitting it. Additional details about the data model, schema, and data generation can be found in the open-sourced data generator. In addition to the schema and data distributions, the data generator provides an example of using multiple writers to ingest data in parallel, using the ingestion scaling of Timestream to ingest millions of measurements per second.
Ingestion workload
We vary the following scale factors representing the use cases we observe across many customers:
- Number of time series – We vary the number of hosts being monitored (100,000–4 million), which also controls the number of time series tracked (2.6–104 million)
- Ingestion volume and data scale – We vary the interval at which data is emitted (from once every minute to once every 5 minutes).
The following table summarizes the data ingestion characteristics and corresponding data storage volumes. Depending on the number of hosts and metric interval, the application ingests between 156 million–3.1 billion data points per hour, resulting in approximately 1.1–21.7 TB per day. These data volumes translate to approximately 0.37–7.7 PB of data ingested over a year.
| Data Scale | Data Interval (seconds) | Number of Hosts Monitored (million) | Number of Time Series (million) | Average Data Points/Second | Average Data Points/Hour (million) | Average Ingestion Volume (MB/s) | Data Size/Hour (GB) | Data Size/Day (TB) | Data Size/Year (PB) |
| Small | 60 | 0.1 | 2.6 | 43,333 | 156 | 13 | 45 | 1 | 0.37 |
| Medium | 300 | 2 | 52 | 173,333 | 624 | 51 | 181 | 4.3 | 1.5 |
| Large | 120 | 4 | 104 | 866,667 | 3,120 | 257 | 904 | 21.7 | 7.7 |
The ingestion and data volumes are for an individual table. Internally, we have tested Timestream at a much larger ingestion scale, upwards of several GB/s ingestion per table, and thousands of databases and tables per AWS account.
Query workload
The query workload is modeled around observability use cases we see across customers. The queries correspond to three broad classes:
- Alerting – Computes aggregate usage of one or more resources across multiple hosts to identify anomalous resource usage (for example, computes the distribution of CPU utilization, binned by 1 minute, across all hosts within a specified microservice for the past 1 hour)
- Populating dashboards – Computes aggregated utilization and patterns across a larger number of hosts to provide aggregate visibility on overall service behavior (for example, finds hosts with resource utilization higher than the average observed in the fleet for the past 1 hour)
- Analysis and reporting – Analyzes large volumes of data for fleet-wide insights over longer periods of time (for example, obtains the CPU and memory utilization of the top k hosts within a microservice that have the highest GC pause intervals, or finds the hours in a day with the highest CPU utilization within a region for the past 3 days).
Each class has two distinct queries: Q1 and Q2 are alerting, Q3 and Q4 are dashboarding, and Q5 and Q6 are analysis.
The alerting queries analyze data for a few thousand hosts for recently ingested data for the past hour. For instance, Q1 and Q2 query an hour of data, where depending on the scale factor, 156 million–3.12 billion data points have been ingested.
The dashboards are populated by analyzing data across tens to a few hundred thousand hosts over 1–3 hours of data. That translates to about 156 million–9.3 billion data points.
The analysis queries process metrics across hundreds of thousands to millions of hosts and span several days of data. For instance, Q6 analyzes 3 days of data, which at the largest scale corresponds to about 60 TB of stored time series data (224 billion data points). You can refer to the preceding table to cross-reference the data sizes and data point count corresponding to the time ranges relevant to the query.
We model many concurrent user sessions running different types of alerts, loading many concurrent dashboards, and multiple users issuing ad-hoc analysis queries or generating periodic reports. We generate concurrent activity by simulating sessions where each session randomly picks a query from the three classes, runs it, and consumes the results. Each session also introduces a randomized think time between two consecutive queries. Each class of query is assigned a weight to resemble what we observe from real workloads that our customers run. For more information, see the open-sourced query workload generator.
Performance and scale
We now present aggregated scale and performance numbers across many different runs. To model typical customer behavior for time series applications, we report all performance numbers where data is continuously being ingested and many concurrent queries are running parallel to ingestion.
Timestream optimizes for good out-of-the-box performance and scale. Timestream automatically identifies table schema, automatically scales resources based on the workload’s requirements, automatically partitions the data, uses query predicates to prune out irrelevant partitions, and uses fine-grained indexing within a partition to efficiently run queries. You can ingest and query using thousands of threads and Timestream automatically adapts as the workload changes.
For these performance runs, we configured a database for each workload size and one table per database. Each table is configured with 2 hours of memory store retention and 1 year of magnetic store retention. We ran continuous data ingest for several months while also running concurrent queries.
For the query workload, we ran a hundred concurrent sessions for each scale factor. Each session ran 50,000 query instances, randomly picking the query to run, with Q1 and Q2 run with 95% probability, Q3 and Q4 run with 4.9% probability, and Q5 and Q6 run with 0.1% probability. Each session also used a think time, randomly picked between 5–300 seconds, between consecutive query runs. We ran the client sessions on an Amazon Elastic Compute Cloud (Amazon EC2) host running in the same Region where the Timestream database was created.
The following plot reports the latency for each query type, Q1–Q6, across the different scale factors. The primary y-axis is the end-to-end query execution time in seconds (plotted in log scale), as observed by the client, from the time the query was issued to the last row of the query result was read. Each session reports the geometric mean of query latency for each query type. The plot reports the latency averaged across the hundred sessions (the average of the geometric mean across the sessions). Each clustered bar corresponds to one scale factor (small, medium, and large; see the table in the preceding section for additional details). Each bar within a cluster corresponds to one of the query types.
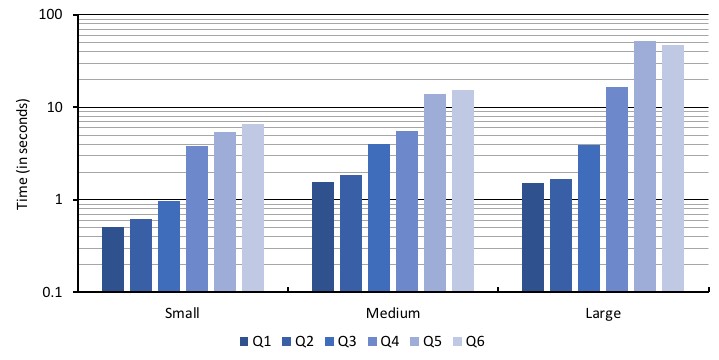
The key takeaways from the query performance results are:
- Timestream seamlessly and automatically scales to ingestion volume of greater than 250 MB/s and tables with petabytes of data. The decoupled ingestion, storage, and query scaling allows the system to scale to time series data of any scale. We internally tested Timestream for several GB/s data ingestion volume. Timestream handles scaling automatically, without any upfront provisioning.
- Even when managing petabytes of time series data and hundreds of millions of time series in a single table, Timestream runs hundreds of concurrent alerting queries, analyzing data across thousands of devices, within hundreds of milliseconds. The latency of these queries remains almost unchanged between the medium- and large-scale factors, where the amount of data ingested increases by more than five times.
- Timestream scales resources depending on the complexity and amount of data accessed by the query. As a result, even as the data volumes increase, the query latency increases by a much smaller factor. For instance, for the dashboarding and analysis queries, we see a data volume increase of approximately 20 times larger, and a 40 times increase in the number of time series monitored between the small- and the larger-scale factors. However, the query latency increase is in the range of two to eight times higher.
- Timestream seamlessly handles concurrent ingestion and queries at large scale and enables you to easily analyze data across millions of time series, combining data in the memory and magnetic store.
Conclusions
In this post, we covered the performance and scale requirements that we observed across many time series applications and in various use cases spanning different industry segments. We used a sample ingestion and query workload representative of customers using Timestream. We saw how Timestream efficiently processes hundreds of millions of time series, seamlessly scales both ingestion and query, and stores petabytes of data across its memory and magnetic storage tiers. We reported on how Timestream’s serverless API runs SQL queries, providing a query response time of hundreds of milliseconds for real-time alerting use cases. The same query interface can also analyze tens of terabytes of time series data to perform sophisticated analysis and derive insights over recent and historical data. We also measured performance at various scale points, showing how the system scales as the data and request volumes for the application grows, so you can design your application once and Timestream automatically scales without needing to re-architect the application.
To facilitate reproducing the scale and performance numbers reported in this post, we’re also making available a sample data ingestion load and query load generator. The workload generators are configurable to enable you to try out different workloads and study the scale and performance characteristics of Timestream. Detailed instructions to use the sample workload generators are included as part of the open-source release. You can explore the getting started experience to understand how Timestream fits your application needs. We also recommend following the best practices guide to optimize the scale and performance of your workload.
About the Authors
 Sudipto Das is a Principal Engineer in AWS working on Timestream. He is an engineering and research leader known for his work on scalable database management systems for cloud platforms. https://sudiptodas.github.io/
Sudipto Das is a Principal Engineer in AWS working on Timestream. He is an engineering and research leader known for his work on scalable database management systems for cloud platforms. https://sudiptodas.github.io/
 Tim Rath is a Senior Principal Engineer in AWS working on Timestream. He is a leading expert in scalable and distributed data management and replication systems, having worked on DynamoDB and several other scalable data platforms at AWS.
Tim Rath is a Senior Principal Engineer in AWS working on Timestream. He is a leading expert in scalable and distributed data management and replication systems, having worked on DynamoDB and several other scalable data platforms at AWS.
