
To migrate an Oracle database to Amazon Aurora with PostgreSQL compatibility, you usually need to perform both automated and manual tasks. The automated tasks involve schema conversion using AWS Schema Conversion Tool (AWS SCT) and data migration using AWS Database Migration Service (AWS DMS). The manual tasks involve post-AWS SCT migration touch-ups for certain database objects that can’t be migrated automatically.
AWS provides a rich set of documentation that makes homogeneous and heterogeneous database migrations easy. For more information about the Amazon Database Migration Playbooks series, which specifies many basic and complex code conversion strategies, see AWS Database Migration Service resources. Each playbook is a step-by-step guide to help make heterogeneous database migrations faster and easier and achieve database freedom.
AWS SCT automatically converts the source database schema and a majority of the custom code to a format compatible with the target database. In database migration of Oracle to PostgreSQL, AWS SCT automates the conversion of Oracle PL/SQL code to equivalent PL/pgSQL code in PostgreSQL. The custom code that the tool converts includes views, stored procedures, and functions. When a code fragment can’t be automatically converted to the target language, AWS SCT clearly documents all locations that require manual input from the application developer.
AWS SCT can automatically convert a few Oracle MERGE statements, but there are some complex scenarios where the database developer has to manually convert the Oracle MERGE code to PostgreSQL. This post covers how to migrate Oracle MERGE and the challenges involved during a conversion.
All the code snippets shown in this post are tested in Oracle – 12.2 and PostgreSQL – 11.
Understanding the Oracle MERGE statement
The MERGE statement was introduced in Oracle 9i, and provides a way to specify single SQL statements that can conditionally perform INSERT, UPDATE, or DELETE operations on the target table—a task that otherwise requires multiple logical statements. The MERGE statement selects records from the source table and automatically performs multiple DML operations on the target table by specifying a logical structure. Its main advantage is to help avoid the use of multiple inserts, updates, or deletes. MERGE is a deterministic statement, which means that after a row is processed by the MERGE statement, it can’t be processed again using the same MERGE statement.
To demonstrate scenarios of Oracle MERGE, we create the following test tables in Oracle database. PRODUCT is the target table and PRODUCT_DELTA is the source whose rows are merged into the PRODUCT table based on the merge condition:
The following INSERT statements insert sample data into the PRODUCT_DELTA and PRODUCT tables:
In the following code, data from the PRODUCT_DELTA table is merged into the PRODUCT table:
For each row in the target PRODUCT table, Oracle evaluates the search condition known as the merge condition. If the condition is matched, the result becomes true and Oracle updates the row in the target table with the corresponding data from the source PRODUCT_DELTA table. If the condition isn’t matched for any rows, the result is false and Oracle inserts the corresponding row from the source PRODUCT_DELTA table into the target table. The following diagram illustrates this workflow.
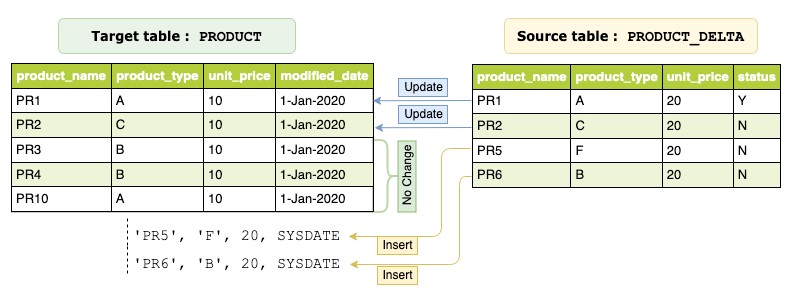
We can verify the target table and check if the data in the PRODUCT table matches the preceding diagram. See the following code:
PostgreSQL doesn’t have a direct MERGE-like construct. However, in PostgreSQL 9.5, the ON CONFLICT clause was added to INSERT, which is the recommended option for many of the Oracle MERGE statements conversion in PostgreSQL. This feature of PostgreSQL is also known as UPSERT—UPDATE or INSERT—and we use UPSERT and ON CONFLICT interchangeably in many places in this post.
We now convert the Oracle MERGE example from earlier to PostgreSQL using ON CONFLICT. The following statements create the PRODUCT and PRODUCT_DELTA tables in PostgreSQL:
You can similarly insert the same dataset into the PRODUCT_DELTA and PRODUCT tables in PostgreSQL as you did in the Oracle database tables:
The following PostgreSQL ON CONFLICT code block is equivalent to the Oracle MERGE, and does the following tasks:
- Inserts rows to the target table from the source table if the rows don’t exist in the target table.
- Updates non-key columns in the target table when the source table has some rows with the same keys as the rows in the target table. However, these rows have different values for the non-key columns.
You can verify the data matches in the Oracle and PostgreSQL PRODUCT table after the code is converted and run in PostgreSQL:
Considerations
You typically need to perform the following while migrating MERGE statements from Oracle to PostgreSQL:
- Remove
FROM DUALif it exists in your Oracle MERGE code. - Remove any table prefix from the UPDATE statement
SETclause. - Don’t include a table prefix for the merge condition columns in the
ON CONFLICTclause. - Verify that the target table has a primary key, unique key, or unique index on the merge condition columns.
The following diagram illustrates the PostgreSQL INSERT INTO .. ON CONFLICT .. DO UPDATE, which is the equivalent of the Oracle MERGE statement for common use cases.

Using ON CONFLICT in PostgreSQL
PostgreSQL ON CONFLICT enables developers to write less code and do more work in SQL, and provides additional guaranteed insert-or-update atomicity. With ON CONFLICT, the record is inserted if not present and updated if the record already exists. One of those two outcomes are guaranteed, regardless of concurrent activity. This is the main reason you gain performance using ON CONFLICT in PostgreSQL while having little or no further thought to concurrency.
Common MERGE use cases
During database migration from Oracle to PostgreSQL, you typically need to understand how PostgreSQL UPSERT with ON CONFLICT differs from Oracle MERGE. In some Oracle MERGE use cases, migrating to PostgreSQL can become challenging. This post explains the following common use cases and recommends best practices:
- Oracle MERGE doesn’t force a unique index to be defined on the column or columns of the MERGE statement’s ON But in PostgreSQL, the target table must have a unique key or unique index on the columns that are part of the
ON CONFLICTclause and guarantees an atomic INSERT or UPDATE outcome. - The MERGE condition contains a function-based comparison.
- The MERGE condition in Oracle describes the minimum requirement by allowing an equi or non-equi joins condition. But in PostgreSQL, the ON expression needs to be evaluated to see if it properly compares to a unique record on the target table.
- Oracle MERGE can contain all or any of INSERT, UPDATE, and DELETE, but PostgreSQL doesn’t support DELETE with
ON CONFLICT.
This post explains all the restraints with ON CONFLICT in detail and shows you how to handle it correctly and efficiently during a database migration process.
Use case 1: The destination table doesn’t have a primary key, unique key, or unique index
A primary key, unique key, or unique index isn’t mandatory for a MERGE statement in Oracle. It just compares rows from the source and target table based on the merge condition specified and runs successfully. However, in PostgreSQL, ON CONFLICT produces the error there is no unique or exclusion constraint matching the ON CONFLICT specification when the target table doesn’t have a primary key, unique key, or unique index for the columns specified in ON CONFLICT.
Therefore, to use the ON CONFLICT clause in PostgreSQL, you must verify if the target table has a primary key, unique key, or unique index created for the condition columns.
For our use case, you have the following condition in your Oracle MERGE statement, which you’re going to migrate to PostgreSQL, and your PostgreSQL destination table doesn’t have a unique index for the condition columns:
Rows that match the preceding merge criteria are updated. Ideally, you must always UPDATE rows based on a unique condition and defining a primary key, unique key, and unique index on the columns makes the job easier. When the table columns that are part of a condition aren’t unique, you might update more than one row, and the result is indeterminate. Therefore, the preceding condition doesn’t guarantee uniqueness, and you might get unpredictable results when the table has duplicate rows for the same condition.
However, PostgreSQL identifies this situation as not a best practice and therefore enforces a unique constraint or index on the columns in ON CONFLICT.
You can create either a primary key, unique key, or unique index on the target table for the condition columns, which helps identify a row in the table uniquely.
The following code creates a primary key for product_name and product_type in the target table in PostgreSQL:
The following code creates a unique key for product_name and product_type in the target table in PostgreSQL:
The following code creates a unique index for product_name and product_type in the target table in PostgreSQL:
After you create the primary key, unique key, or unique index on the destination table, you can follow the ON CONFLICT example explained earlier to migrate your Oracle MERGE code.
Use case 2: The MERGE condition contains a function-based comparison
In an Oracle MERGE statement, the ON clause specifies the condition upon which the MERGE operation either updates or inserts. Oracle provides a much more flexible way of writing merge conditions by allowing any operator or function in the merge condition. However, in PostgreSQL, the target table must have a unique index for the columns or conditions specified in the ON CONFLICT clause.
For example, if you have the following merge condition in a MERGE query in Oracle, you need to create a unique index in PostgreSQL for the exact matching merge condition specified in the Oracle MERGE join condition:
In PostgreSQL, creating a unique index on product_name and product_type for this use case doesn’t work, because this isn’t the equivalent condition for the Oracle merge condition. You get the there is no unique or exclusion constraint matching the ON CONFLICT specification error if you create the following index:
These types of Oracle MERGE statements are bit tricky to migrate in PostgreSQL. Following the best practices in PostgreSQL, you must check if an exact functional unique index exists in PostgreSQL or not. If not, you must create a functional unique index in PostgreSQL and can convert code to the equivalent ON CONFLICT:
The following code demonstrates how you can migrate Oracle MERGE to PostgreSQL when you have a complex MERGE join condition:
The following code creates a unique functional index in PostgreSQL and illustrates how you can migrate Oracle MERGE statements to PostgreSQL when the merge condition isn’t an equi-join or contains a functional comparison:
Use case 3: The MERGE condition isn’t an equi-join
Oracle MERGE uses the ON clause to specify the condition, which can take any available operator. Based on the result of the condition, the MERGE operation either updates or inserts rows into the target table. You may sometimes encounter use cases in Oracle that need additional considerations when migrating to PostgreSQL.
For example, we use the following Oracle MERGE use case and migrate to PostgreSQL:
The following PostgreSQL code is the equivalent migrated code for the preceding Oracle MERGE:
Use case 4: PostgreSQL doesn’t support DELETE with ON CONFLICT
You can add an optional DELETE WHERE clause to the MATCHED clause to clean up after a merge operation. The DELETE clause deletes only the rows from the target table for which both the ON clause and DELETE WHERE clause conditions evaluates to TRUE.
When using MERGE for the DELETE operation, you must remember the following:
- DELETE checks the match condition on the target table, not the source.
- First the UPDATE SET … WHERE operation is performed, then the DELETE WHERE clause condition takes the updated value for its evaluation, not the original value from the table.
- DELETE works only on rows updated during MERGE. Any rows in the target table that aren’t processed during
MERGEaren’t deleted, even if they match the DELETE condition.
Migrating MERGE statements containing INSERT, UPDATE, and DELETE
Let’s examine a use case to understand how you can migrate a complex Oracle MERGE statement to PostgreSQL, which contains INSERT, UPDATE, and DELETE clauses in a single operation:
- Insert rows to the
PRODUCTtable from thePRODUCT_DELTAtable if the rows don’t exist in the PRODUCT - Update non-key columns in the
PRODUCTtable when thePRODUCT_DELTAtable has some rows with the same keys as the rows in thePRODUCTtable. However, these rows have different values for the non-key columns. - Delete matching rows from the
PRODUCTtable whenstatus = ‘Y’in thePRODUCT_DELTA
See the following code:
We can check the rows in the PRODUCT table:
Because you can’t delete rows using the ON CONFLICT clause in PostgreSQL, it becomes very tricky to migrate such code to PostgreSQL. As database developers, you can write code in many ways, but it’s essential to know which is the best option for a particular problem statement. In this section, we explore some workarounds for this use case and identify the best option.
Creating UPSERT with ON CONFLICT + DELETE with CTE
You can only insert or update based on the matching columns through the ON CONFLICT clause. To achieve DELETE in the same statement as ON CONFLICT in PostgreSQL, you can use CTE (common table expression) to perform DELETE and ON CONFLICT for UPSERT. But if the statements aren’t organized correctly, it might produce erroneous output. Therefore, it’s important during a conversion to refactor code correctly and test properly. A little negligence during code migration could lead to functional abnormalities and data corruption.
The following code runs correctly but has several semantic error and race conditions:
Compare the output of the PRODUCT table in Oracle and you can identify the data mismatches:
This approach has the following issues:
- The preceding query isn’t prevented from being used concurrently. To avoid race conditions on a busy database, a LOCK TABLE command is required, which is even more reason to speed up the INSERT/UPDATE transaction.
- The organization of DML commands in the query doesn’t really rival with Oracle MERGE . This means in an Oracle MERGE statement; the run order is first UPDATE, followed by DELETE, and finally INSERT. Also, DELETE works only on rows updated during MERGE.
Breaking Oracle MERGE into individual DML statements
You can break Oracle MERGE to individual DML statements in PL/pgSQL in the same order MERGE is performed. A good way to implement this idea is with a manual lock command:
LOCK TABLE <destination table> IN SHARE ROW EXCLUSIVE MODE;
That lock level isn’t automatically acquired by any PostgreSQL command, so the only way it helps you is when you’re running concurrent transactions. When you know that no UPSERTs overlap through concurrent transactions or sessions, you can omit that lock. See the following code:
For more information about locks, see Explicit Locking.
Using one statement to INSERT, UDPATE, and DELETE using CTE
Although the preceding method is logical and easy to follow, the reason for moving to a single statement is to improve performance and reduce the chance of race conditions. See the following code:
Conclusion
This post covered the most common types of MERGE statements used in Oracle and explained how you can convert them to equivalent PostgreSQL code. This post may be helpful if you’re experiencing issues with MERGE statements while migrating from an Oracle database to a PostgreSQL database.
If you have other issues not covered by these solutions, please leave a comment.
About the Authors
 Venkatramana Chintha is an Associate Consultant with the Professional services team at AWS.
Venkatramana Chintha is an Associate Consultant with the Professional services team at AWS.
He works with AWS Technology and Consulting partners to provide guidance and technical assistance
on homogeneous and heterogeneous database migrations and Re-hosting migrations
 Sashikanta Pattanayak is an Associate Consultant with the Professional services team at AWS.
Sashikanta Pattanayak is an Associate Consultant with the Professional services team at AWS.
He works with customers to build scalable, highly available and secure solutions in the AWS cloud.
He specializes in homogeneous and heterogeneous database migrations.
