You can use SPARQL 1.1 Federated Query to get data from multiple different SPARQL endpoints and join the results together into a single result set for further analysis. This is done with the SERVICE keyword:
SERVICE <http://dbpedia.org/sparql>
For more information, see SPARQL 1.1 Federated Query.
When you create a new Amazon Neptune cluster on the AWS Management Console with the default configuration, Amazon Neptune can’t make SPARQL 1.1 federated queries, due to the default Amazon Virtual Private Cloud (Amazon VPC) network configuration in place.
In this post, I describe firstly how you can create a new Amazon Neptune cluster on the console. then by using a NAT Gateway configure your Amazon VPC network to enable SPARQL 1.1 Federated Query.
For more information about how to use Amazon VPC, including guides, example code, developer tools, blogs and more visit Amazon VPC resources.
The images, links, and steps referencing the AWS Management Console were correct at the time of writing. However, be aware that the console changes over time and may not look exactly the same as you follow along.
Please take into consideration costs when using Amazon VPC, as different components have different costs associated. Navigate to VPC Pricing for more information.
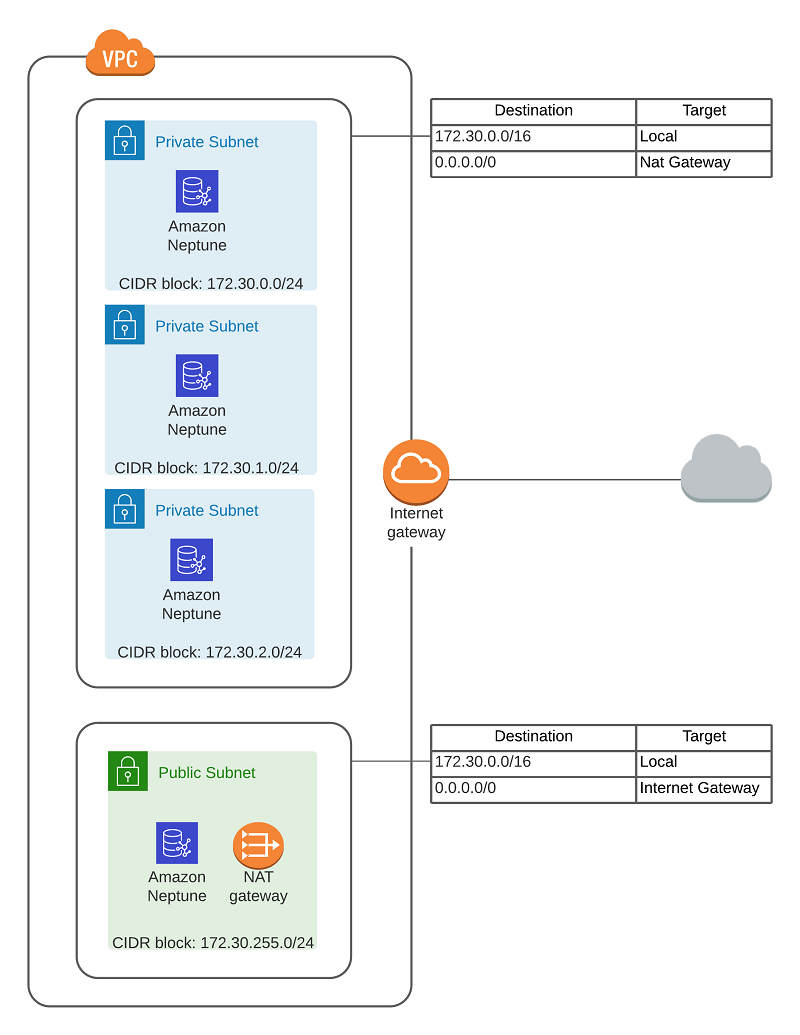
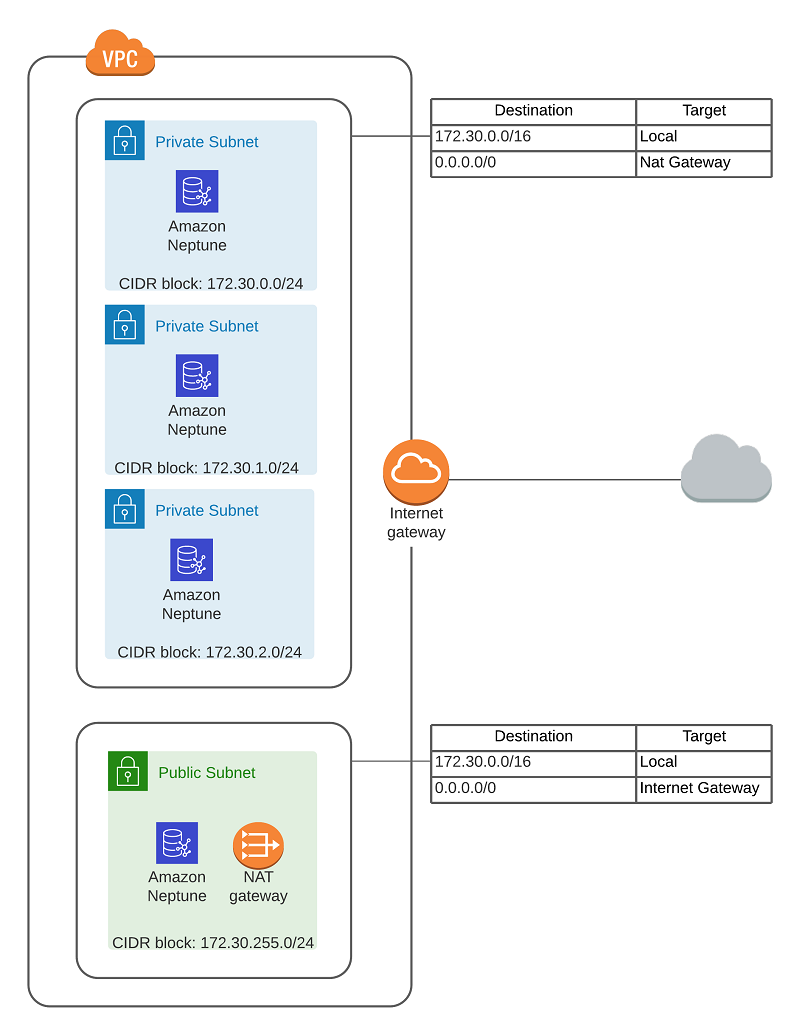
I will describe how you can create the following Amazon VPC Configuration to enable an Amazon Neptune cluster to communicate with other external SPARQL 1.1 endpoints, enabling SPARQL1.1 Federated Query:
Using an existing Neptune cluster
If you already have an existing Neptune cluster and want to make federated queries, you can still follow this post. Start at Step 5 (locating your VPC identifier) in the Creating your cluster and configuring your network section.
To test if your Neptune SPARQL 1.1 endpoint can run federated queries, run the following query:
Creating your cluster and configuring your network
To create a new Neptune cluster and set up VPC network configuration, complete the following steps:
- On the Amazon Neptune homepage, choose Launch Amazon Neptune.
- When creating a new VPC for your Neptune cluster, keep settings at their defaults until you reach the Connectivity
- For Virtual Private Cloud (VPC), choose Create new VPC.
This makes it easier to maintain the configuration separately, and if you make a mistake, you can always delete the VPC and start again without affecting other services.
- When creating your Neptune cluster, leave the settings at their defaults.
- Choose Create database.
- When the cluster is running, navigate to your instance on the Neptune console and record the VPC identifier.
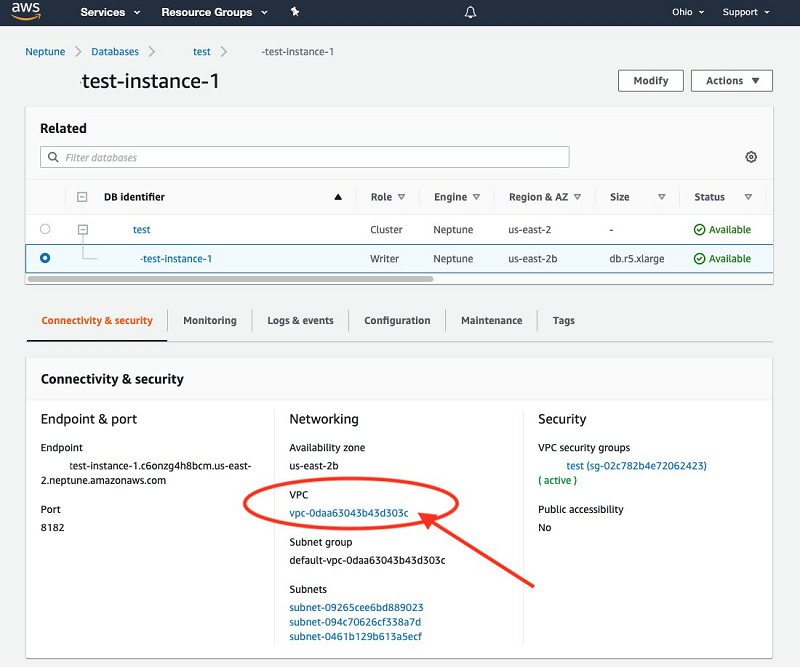
You’re now ready to create a new subnet.
- On the console, navigate to
services/vpc/subnets. - When creating your subnet, choose the VPC that was created with your Neptune cluster and a suitable CIDR block.
For this post, the VPC has a CIDR block allocation of 172.30.0.0/16, and Neptune already created three other subnets and a routing table using CIDR blocks 172.30.0.0/24, 172.30.1.0/24, and 172.30.2.0/24. You need to allocate another CIDR block, so I used 172.30.255.0/24.
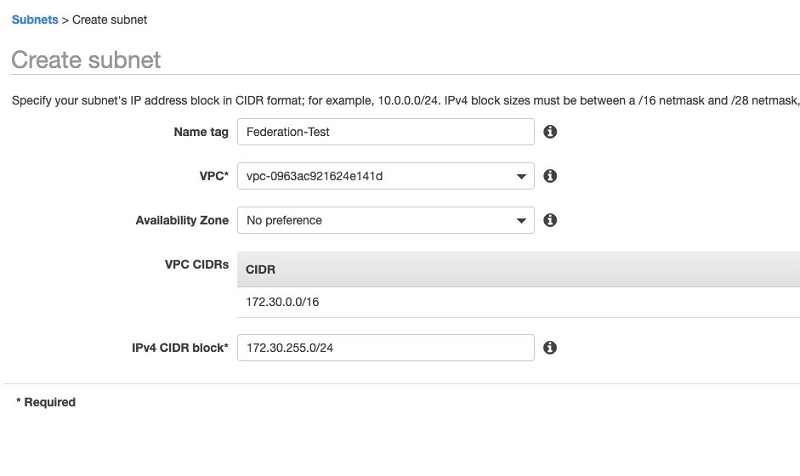
In the next step, you create a new NAT gateway.
- On the console, navigate to
services/vpc/NatGateways - When creating your gateway, link it to the subnet you just created.
- To get a new IP address to use, choose Allocate IP Address.
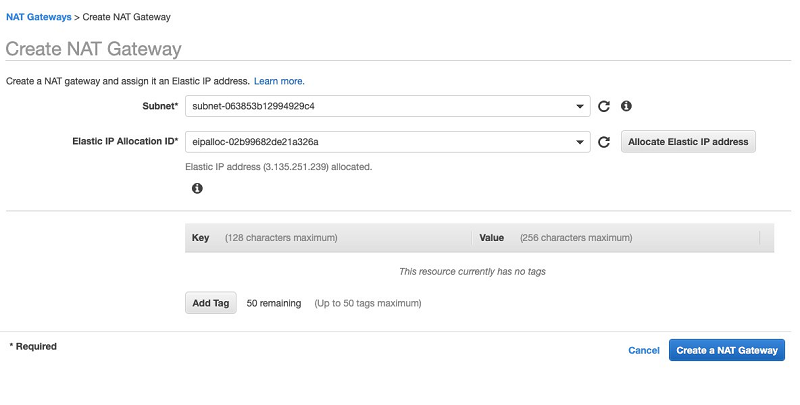
In the next step, you allocate subnets to the correct route tables.
- Navigate to
services/vpc/RouteTables - Under Route tables, choose the route table created for your Neptune instance.
- Allocate all the subnets (except the new one you created) to this table.
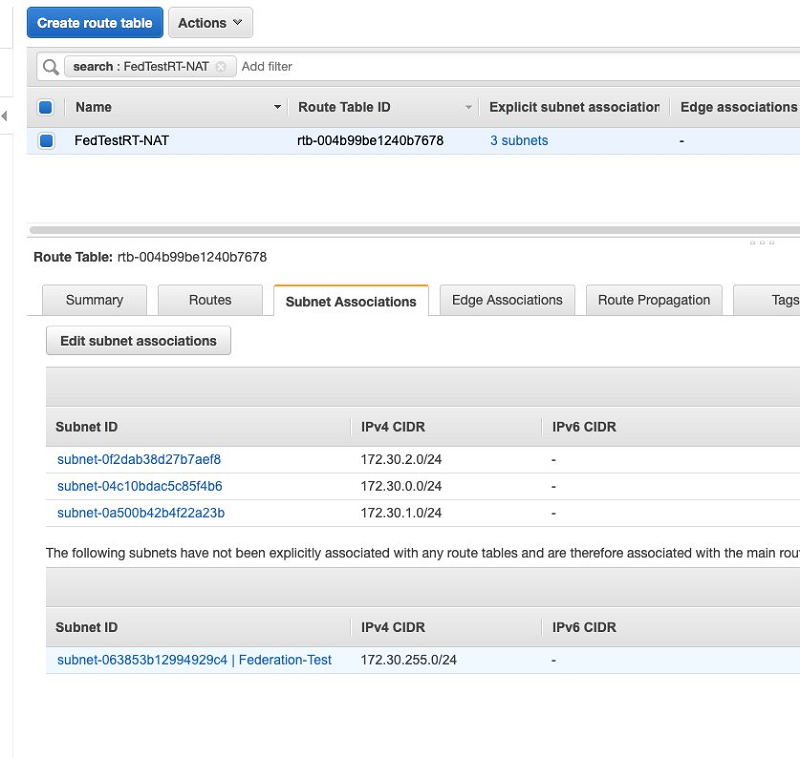
You will create another route table for your new subnet later.
You can now target your new NAT gateway.
- On the Routes tab, for the same route table, set the target for the destination 0.0.0.0/0 to your new NAT gateway.
The input field for the target can be a bit confusing because it defaults to the internet gateway for your VPC. It looks like the list to choose from only has one value, if you choose the box and delete the value, you can choose the NAT gateway.
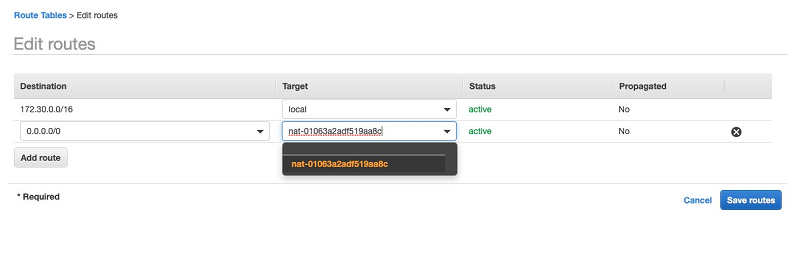
- Now click Save Routes.
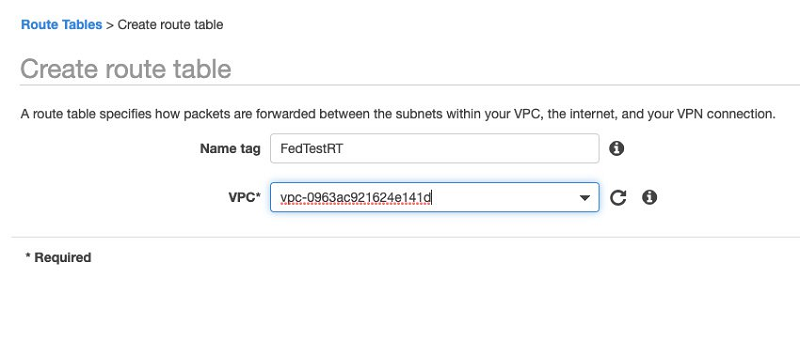
- Choose Create new route table.
- For VPC, enter the VPC to link the table to.
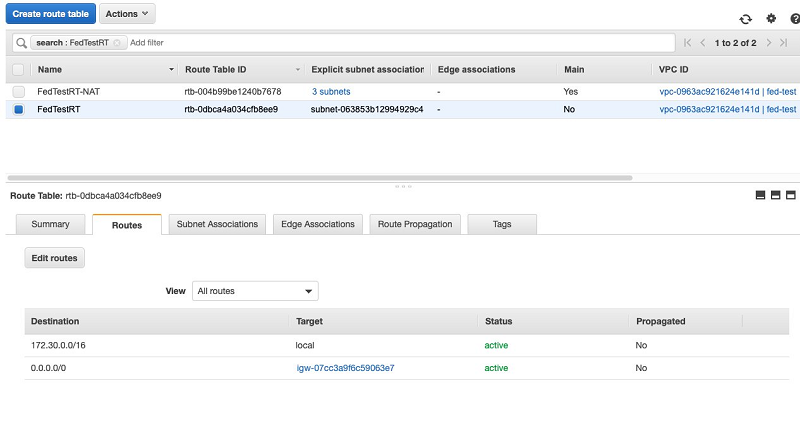
When you created your Neptune cluster, you also created an internet gateway automatically. You need to link your new route table to this gateway.
- Navigate to your new route table.
- On the Routes tab, add a new route with a destination of 0.0.0.0/0 and the target of the internet gateway for your VPC.
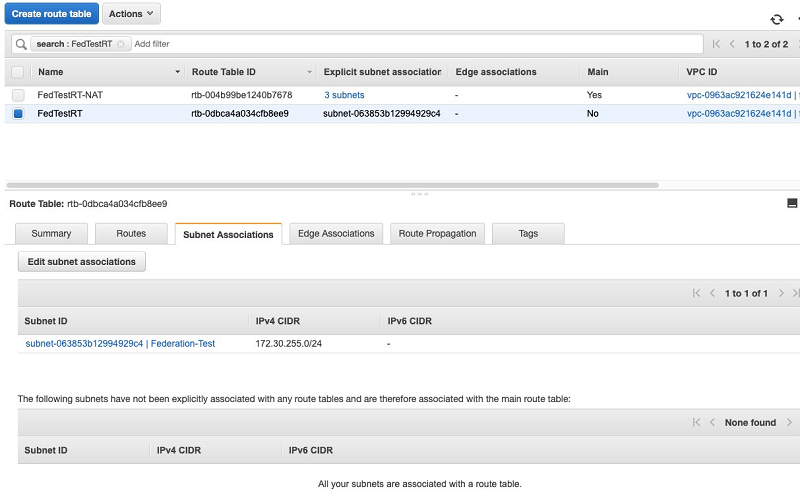
- On the Subnet Associations tab, edit subnet associations and associate your new subnet with your new route table.
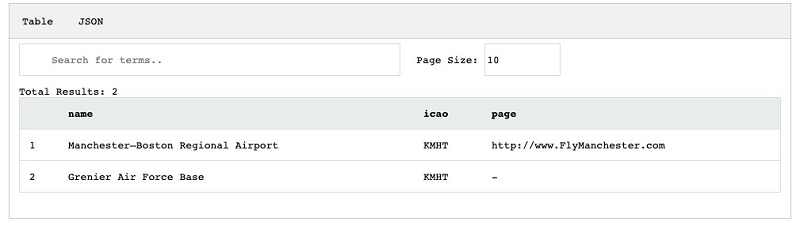
You should now be able to run the following query successfully:
You can expect a result set similar to the following screenshot.
Summary
This post examined how to configure your VPC to enable running SPARQL 1.1 Federated Query with Amazon Neptune. You can now combine data from as many SPARQL 1.1 endpoints as you like.
Using Neptune allows you to benefit from the W3C recommendations of RDF and SPARQL for your application and satisfies the operational business requirements of business-critical applications, including cost optimisation, better integration with native cloud tools, and lowering operational burden.
We hope that this post provides you with the confidence to get started with SPARQL 1.1 Federated Query on Amazon Neptune. If you have any questions, comments, or other feedback, we’re always available through your Amazon account manager or via the Amazon Neptune Discussion Forums.
About the Author
 Charles Ivie is a Senior Graph Architect with the Amazon Neptune team at AWS. He has been designing, implementing and leading solutions using knowledge graph technologies for over ten years.
Charles Ivie is a Senior Graph Architect with the Amazon Neptune team at AWS. He has been designing, implementing and leading solutions using knowledge graph technologies for over ten years.
