While the cloud continues to grow in popularity for many, if not most, enterprise applications, IT departments remain reluctant to trust public clouds, including the Google Cloud Platform, for business-critical Microsoft SQL Server applications. Their primary concern is the increased risk and complexity of running Microsoft SQL Server, and optionally Microsoft’s Windows Server Failover Clustering (WSFC), in environments where high-availability clustering configurations are often less robust and more expensive than they are in a private enterprise cloud.
Among the issues for SQL Server is the need to use shared storage for Always On Failover Cluster Instances. This is a problem for two reasons. First, shared storage in the form of a storage area network (SAN) is not available in the Google Cloud Platform. Second, shared anything creates a single point of failure when not also made fully redundant.
One way to overcome such limitations involves implementing third-party failover clustering software within the Google Cloud. When designed to support SQL Server, the failover cluster creates a high-performance, high-availability environment that is easy to manage.
Limitations on SQL Server high availability in the Google Cloud
Like other cloud services, the Google Cloud Platform offers application failover capabilities for many applications requiring high availability. These services work by replicating data from the master instance to one or more replica instances in different zones, which are normally located in different data centers to protect against localized disasters. In the event of a failure in the application’s master instance, the high-availability provisions fail over to a replica instance.
In the Google Cloud (as of this writing), the standard high-availability provisions have the following five limitations:
- Failovers are normally triggered only by a zone outage, which is only one of the many reasons applications fail.
- Each master can create only a single failover replica, thereby creating a single point of failure.
- Backups must be performed using the master data set, thereby making planned downtime inevitable.
- The use of event logs to replicate data creates a “replication lag” that causes temporary outages during a failover.
- The service currently supports only MySQL and PostgreSQL, but not SQL Server.
While these limitations might be acceptable as part of a disaster recovery strategy for some applications, they are unacceptable for mission-critical SQL Server applications. To support high availability in public, private, and hybrid clouds, SQL Server offers its own solution with Always On Availability Groups in the Enterprise Edition. But this premium capability also comes at a premium price that cannot be justified for many database applications.
SQL Server Standard Edition includes Always On Failover Clustering, which leverages Windows Server Failover Clustering built into the operating system. While getting this to work well in the Google Cloud is possible, it requires using third-party SAN-less failover clustering to take the place of the SAN and allow locally attached storage to be used in a failover cluster.
Adding a SAN-less failover cluster to the Google Cloud
SAN-less failover clustering software is purpose-built to create just what the name implies: a storage-agnostic, shared-nothing cluster of servers and storage with automatic failover for application availability. As a high availability solution, SAN-less clusters are capable of operating across both the LAN and WAN in private, public, and hybrid clouds. These clusters are also extensible, enabling organizations to have a single, universal high-availability solution across most applications.
Most SAN-less failover clustering software provides a combination of real-time, block-level data replication, continuous application monitoring, and configurable failover/failback recovery policies to protect business-critical applications, including those using the Always On Failover Clustering feature in SQL Server Standard Edition.
Some of the more robust SAN-less failover clustering solutions also offer advanced capabilities, such as ease of configuration and operation with an intuitive graphical user interface, a choice of synchronous or asynchronous replication, WAN optimization to maximize performance, manual switchover of primary and secondary server assignments for planned maintenance, and performing regular backups without disruption to the application.
Configuring SQL Server failover cluster instances in the Google Cloud
This section outlines the process used to configure a simple two-server failover cluster across the Google Cloud Platform’s zone-based infrastructure. Configurations involving three or more servers are also possible using the same basic process.
The example uses SIOS DataKeeper Cluster Edition to create the SAN-less failover cluster. SIOS DataKeeper uses block-level replication to ensure that the locally attached storage on each SQL instance remains synchronized. SIOS DataKeeper also integrates with Windows Server Failover Clustering through its own storage class resource called a DataKeeper Volume, which takes the place of the physical disk resource. Within the cluster, the DataKeeper volume appears to be a physical disk, but instead of controlling SCSI reservations, it controls the mirror direction, thereby ensuring that only the active server writes to the disk and that passive servers receive all the changes, either synchronously or asynchronously.
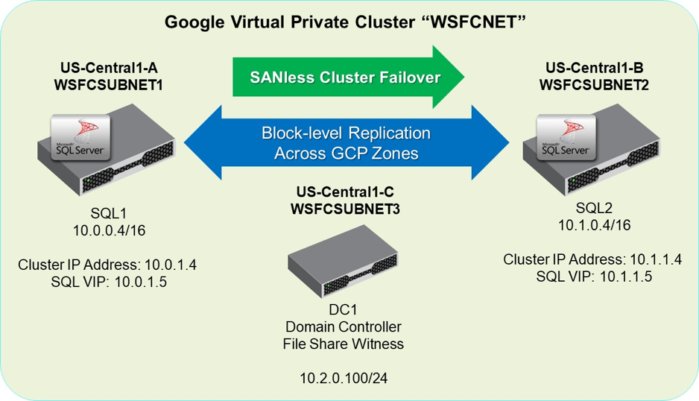
The architecture for a SAN-less failover cluster configured as a virtual private cloud (VPC) is shown in the diagram below. There are two SQL Server nodes in different zones (1-A and 1-B) in the US-Central region. The File Share Witness, which is needed to configure a quorum in Windows clusters, is performed by the domain controller in US-Central zone 1-C. Keeping each instance of the quorum in a different zone eliminates the possibility of losing more than one vote if an entire zone goes offline. Also shown are the VPC’s node names, IP addresses, and subnet values that will be configured in the steps that follow.
SIOS
Shown here is the final configuration of the SAN-less failover cluster for the Google virtual private cloud.
Failover clusters are created in the Google Cloud in much the same way they are created in a private cloud, but with one important difference: You can’t use a single subnet with a single virtual IP address that moves among cluster nodes, owing to GCP’s lack of support for gratuitous ARP (address resolution protocol). It is possible to get around this limitation by following procedures outlined here that place each node in a different subnet, and then create host-specific routes for the cluster IP addresses. Note that the discussion assumes the reader is familiar with both the Google Cloud and IP address subnetting.
Step #1: Create the VPC network and failover cluster instances
In this example the VPC, named WSFCNET, has three subnets: WSFCSUBNET1, WSFCSUBNET2, and WSFCSUBNET3 in three different zones (10.0.0.0/24, 10.1.0.0/24, and 10.2.0.0/24) for SQL1, SQL2, and DC1, respectively. Using the Google Cloud Platform console, each node will initially be given a static IP address with forwarding in the /24 subnet; however, we will change all of the SQL nodes to a /16 subnet mask to support host-specific routing. This step also involves creating firewall rules to permit communications among the VPC nodes.
Here is the command for creating WSFCSUBNET1:
gcloud compute networks subnets create wsfcsubnet1 --network wsfcnet
--region us-central1 --range 10.0.0.0/24
The SQL1 and SLQ2 failover cluster instances use standard Windows Server 2016 images with SQL Server pre-installed, but the SQL Server software will need to be re-installed as a clustered instance after the basic cluster is created in step #3. The DC instance also uses a standard Windows Server 2016 image.
Step #2: Update the IP addresses and routes
With DC1 connected and designated as the domain controller, the IP addresses for the SQL Server instances are changed using the netsh command to have a /16 subnet mask to support host-specific routing. The netsh command is also used to set the DNS address. The gcloud compute routes create command on the Google Cloud Platform console is then used to create four routes, with both a route and a route listener for SQL1 and SQL2.
Here are the commands for updating the address for SQL1:
netsh interface ip set address name=ethernet static 10.0.0.4 255.255.0.0 10.0.0.1 1
netsh interface ip set dns ethernet static 10.2.0.100
And here are the commands for creating the route and route listener for SQL1:
gcloud compute routes create cluster-sql1-route --network wsfcnet
--destination-range 10.0.1.4/32 --next-hop-instance sql1
--next-hop-instance-zone us-central1-a --priority 1
gcloud compute routes create cluster-sql1-route-listener
--network wsfcnet
--destination-range 10.0.1.5/32 --next-hop-instance sql1
--next-hop-instance-zone us-central1-a --priority 1
Step #3: Create the cluster
With the IP addresses and routes specified, the cluster is created by running PowerShell commands to enable failover clustering, as well as to validate and create the cluster, which also designates its name and member node IP addresses. With the cluster created, the quorum properties and permissions are changed to create a file share on DC1, and to give the cluster nodes read/write permissions at both the share and NTFS level.
Here is the PowerShell command for enabling the failover clustering feature on the two SQL nodes:
Install-WindowsFeature Failover-Clustering –IncludeManagementTools
This PowerShell command is then used to validate the cluster:
Test-Cluster -Node sql1, sql2
Finally, the cluster is created by running the New-Cluster command from either SQL1 or SQL2:
New-Cluster -Name cluster1 –Node sql1,sql2 -NoStorage -StaticAddress 10.0.1.4,10.1.1.4
After creating the file share on DC1, the File Share Witness is added using the following PowerShell command:
Set-ClusterQuorum -NodeAndFileShareMajority dc1quorum
Step #4: Install the SQL Server instances
The final step involves installing the SQL Server software on the two nodes (SQL1 and SQL2) in the failover cluster. This step also involves configuring SIOS DataKeeper to replicate the locally attached disks between server instances, and registering a DataKeeper Volume Resource in Failover Clustering. Synchronous replication is normally used for mirroring within a Google Cloud Platform region, as is the case in this example. Mirroring with a third node in a separate region would use asynchronous replication.
The devil is always in the details, of course, and the complete details involved in configuring a Google Cloud VPC for failover clustering are beyond the scope of this article. Complete step-by-step instructions, including with fully detailed commands and screen shots, are available in the SIOS white paper, “How to Build a SAN-less SQL Server Failover Cluster Instance in Google Cloud Platform with SIOS DataKeeper.” While some of the screens and settings are specific to SIOS DataKeeper, the configuration requirements are fully applicable to any SQL Server failover cluster solution.
David Bermingham is a high availability expert and eight-year Microsoft MVP, six years as a Cluster MVP and two years as a Cloud and Datacenter Management MVP. David’s work as director at SIOS Technology has him focused on evangelizing Microsoft high availability and disaster recovery solutions and providing hands-on support, training and professional services for cluster implementations. Email David at David.Bermingham@us.sios.com and learn more at us.sios.com and www.ClusteringforMereMortals.com.
—
New Tech Forum provides a venue to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to newtechforum@infoworld.com.
