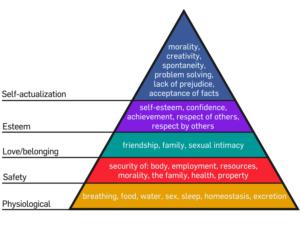
Abraham Maslow introduced his now-famous hierarchy of needs in 1943, proposing that people had to achieve a sequential set of conditions to attain complete fulfilment. The five levels of the hierarchy were represented as a pyramid to convey the idea that higher levels, such as self-actualization, could not be reached until lower levels, such as basic physiological needs, were first conquered.
Maslow’s original hierarchy of needs
A few years ago, LinkedIn’s engineering leader Kevin Scott (now CTO and SVP at Microsoft) created a Maslow-inspired “Engineering Hierarchy of Needs” to help guide the development of our technology organization. Following this hierarchy helped us ensure we had solid fundamentals in place when implementing new product versions. LinkedIn’s well-publicized Project InVersion in 2011 occurred before this engineering hierarchy was created; however, it’s an example of reasserting the order of the hierarchy when it had gotten off balance, given that we froze new product development for several months while concentrating on rebuilding basic infrastructure.
 Kevin Scott/LinkedIn
Kevin Scott/LinkedIn
LinkedIn’s Engineering Hierarchy of Needs
As pictured above, the levels of the hierarchy, in ascending order, are site up and secure; technology at scale; development at scale; solid APIs and building blocks; efficiency; and magic. Without the fundamental levels in place and functioning well, engineering organizations will never be able to produce features and products that delight both their creators and end users, which is the true “magic” of software engineering.
While all the levels of the hierarchy are important, I’m going to focus on the bottom three, as they are areas that many engineering organizations struggle with when trying to scale.
Site up and secure
The layers of the hierarchy often map to an engineering organization’s maturity, so for new startups or teams, the first step is always to focus on site uptime and security. This may seem intuitive, but in the rush to begin delivering exciting new features, organizations may be tempted to jump over this level before it’s fully achieved.
This initial layer is so crucial because it doesn’t matter if your product has amazing features if it’s constantly crashing, because no one will stick around to actually use it. Similarly, a security flaw can completely cripple a product and render it essentially useless—not to mention the major blow to corporate trust and overall reputation. This is why the fundamentals needed for uptime and security must be in place before any other development occurs.
Some key elements of site up include: implementing the monitoring and management of your systems, failover planning for servers and whole data centers, agreed-upon metrics used to regularly evaluate site speed and performance, and dedicated engineers (such as SREs) prepared to address any unforeseen crashes in a timely manner. In 2012, the startup I worked for used a cloud company for 50 percent of our hosting. There was a bad storm in Ireland, taking out the main power supply at a data center. This required us to failover all EU traffic to east coast data centers in less than two minutes. Fortunately, a few years prior to this event, the company had instituted a practice of monthly failover testing to ensure the systems were able to support the sudden increase in traffic.
Technology at scale
Many organizations face the challenge of technology at scale once they have achieved site up and secure and are suddenly seeing a rapid increase in the number of end users. They quickly realize that they need to iterate on their basic infrastructure to make sure that the architecture is scalable.
Another way of thinking about this level is to ask yourself if your product is prepared to handle a sudden 5X increase in users, and then to test it at that load. If the results show it is not ready, then you need to focus on making your infrastructure more scalable. In addition, you need to start building out the tools to manage systems and their dependencies, to build up the automated performance infrastructure, and to teach your engineers how to run performance tests to ensure metrics of resource consumption are constantly emitted for analysis. You should always be aware of how your systems perform at 50 percent load and 99 percent load. This allows you to determine how gracefully the systems will degrade.
Development at scale
This step is pivotal as an engineering organization begins to grow. Success at this level of the hierarchy looks like an organization that can seamlessly add new engineers to their team and where developers can work productively.
At LinkedIn, the major component of this level is our continuous integration and delivery philosophy. To scale our process, we moved away from branch-based development to trunk-based development. We strive to deploy code no less than three times per day, with no more than three hours from initial commit to when it’s live in production. Many startups implement branch-based development and continuous integration, but then stop there. While these are great first steps for ensuring quality, moving to trunk-based development puts a high level of emphasis on complete integration testing and one-button push to production. This allows developers to be more productive and get immediate feedback on their improvements to the product.
There are several tools that can help facilitate continuous delivery, but some of the most important pertain to testing. In order to remain confident in code that’s shipped quickly, you need a robust system for unit testing, integration testing, a method for canary testing, and a well-defined ramping process, among other elements.
Being able to easily create new products in a scalable way makes for a much more pleasant work experience. Developer happiness is something we measure for regularly at LinkedIn, and when we see problems, it’s evident when we survey our developers—indicating a need for improvements in our tools or infrastructure. We measure developer happiness regularly to determine whether we have improved the development experience or not.
Following the hierarchy: a continual effort
As companies look to incorporate the Engineering Hierarchy of Needs, it’s important to remember that climbing the pyramid isn’t a one-way trip. The strongest engineering organizations are continually evaluating their progress against the hierarchy and are willing to make changes at lower levels as needed in order to truly fulfill the upper levels.
At first glance, it may seem less fun or exciting to start with the basics before moving on to fancy updates or cool new features. But in reality, those highest levels of engineering fulfilment are impossible to attain without a strong foundation in place.
This article is published as part of the IDG Contributor Network. Want to Join?
