
MySQL Ndb Cluster provides durability for data by default via logging and checkpointing.
In addition, users can take backups at any time, which allows for disaster recovery, replication synchronisation, data portability and other use cases.
This post looks at the backup and restore mechanisms in MySQL Ndb Cluster.
MySQL Ndb Cluster architecture recap
MySQL Ndb Cluster is a distributed SQL relational database :
- Designed for low overhead read + write scale out, high availability, high throughput and low latency.
- Providing distributed parallel joins, transactions, row locks, foreign keys.
- Data is primarily stored and managed by a set of independent data node processes.
- Data is accessed via distributed MySQL servers and other clients.
- Performance
- Scale out read + write : Tables and indices are distributed across data nodes.
- Scale up read + write : Tables and indices are distributed across Local Data Manager (LDM) components within each data node, with parallel checkpointing and redo logs.
- Scale out + up of read + write : Fully parallel and distributed transaction prepare + commit.
- High availability :
- Tables and indices transactionally replicated across data nodes for high availability, locality, read scaling.
- Automatic logging, checkpointing, failure detection, failover, recovery, resynchronisation
- Online operations : Backup, schema changes, upgrade.
- MySQL compatibility, async replication between clusters and InnoDB, connectors, 3rd party support.
MySQL Ndb Cluster is a superset of the MySQL Server functionality, and users may use a mix of Ndb and InnoDB tables and features.
Ndb backup + ndb_restore
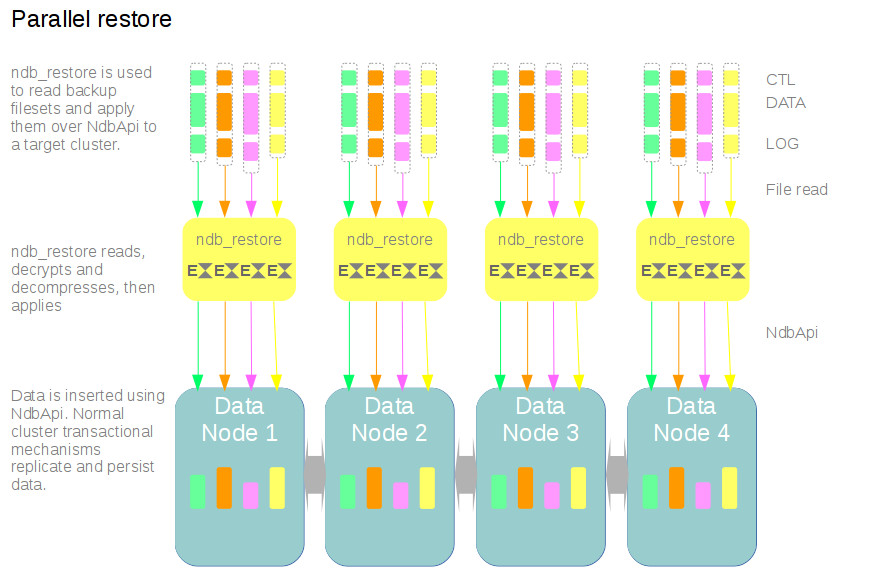
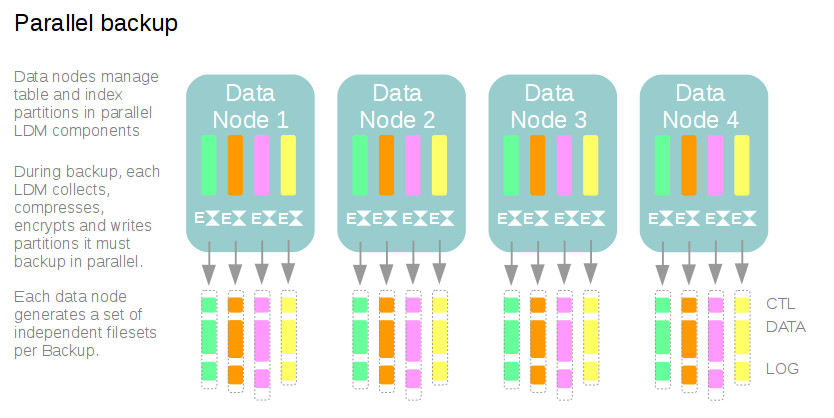
MySQL Ndb Cluster has a built-in backup mechanism called Ndb backup. Ndb backup captures the state of all of the tables and indexes stored in the cluster data nodes, allowing them to be restored to a transactionally consistent point in time. As this data is partitioned and distributed across the cluster data nodes, the backup is also partitioned and distributed, with each data node producing a standalone set of backup filesets containing a subset of the cluster’s data. Restoring all of the backup filesets results in restoring all of the cluster’s data.
Ndb backup filesets are restored using a tool called ndb_restore. This tool can read the filesets generated by Ndb backup, and uses NdbApi to efficiently restore the data to a target cluster. The backup files contain a logical rather than physical format – restoration is effectively re-insertion and modification of rows.
This design allows ndb_restore to be flexible about restoring data, supporting :
– Restore to a different target schema (1, 2, 3, 4, 5, 6)
– Restore of a subset of tables and indices (1, 2, 3, 4)
– Restore to a different table or index distribution
– Restore to a different cluster size or topology
– Restore to a different cluster software version
– Restore to a different hardware or OS platform
– Remote restore across a network

As the backup is partitioned into logical shared-nothing filesets, the restore is also naturally partitioned and parallelised for minimal restoration time.
Note that Ndb Backup captures only the data stored in the data nodes, e.g. tables with ENGINE=NDB[CLUSTER]. InnoDB tables and indices, and other MySQL Server local objects such as Triggers, Stored procedures and Views must be backed up and restored using different mechanisms such as mysqldump.
Binary logs
Each Ndb Backup captures the state of a cluster at a transactionally consistent point in time, represented in Ndb as an epoch number. Epoch numbers are also used in MySQL Ndb Cluster as transactional Binary log markers, dividing the parallel flow of committed transactions into consistent units. This transactional alignment between backups and binary logs makes it easy to setup and manage async replication between clusters, and implement point in time recovery solutions. The binlog position corresponding to a backup can be precisely determined, and replication can be established from that point onwards.
Indexes and Constraints
MySQL Ndb Cluster supports secondary unique and ordered indexes, and transactional foreign key constraints. Unique and foreign key constraints are not enforceable until backup restoration is complete, and maintaining secondary indexes during data restoration consumes resources. ndb_restore has options to temporarily disable and then rebuild secondary indexes and constraints around the bulk data loading phase of restore allowing :
– Optimised restoration without the need to maintain indexes, check constraints
– Avoidance of dependency problems with e.g. circular foreign key references, self references etc
– Optimised parallel index build
All constraints are naturally checked as part of the constraint rebuild, so integrity is enforced.
Schema changes
Ndb backup filesets capture the schema of tables and indices. ndb_restore uses this information to recreate tables and indexes prior to restoring data.
When restoring data, ndb_restore compares the schema of tables and indexes in the target cluster to those captured in the backup. ndb_restore optionally allows a number of differences, e.g. in numbers of columns, type widths etc, so that data captured from an old schema version can be restored into a new schema without intermediate transformation steps.
Recent versions have added support for column remapping, where data can be transformed, and changes to the set of primary key columns, allowing distribution optimisations.
These features can be used alongside the schema flexibility features of MySQL asynchronous replication, allowing replication to be established and synchronised from an old schema cluster to a new schema cluster, and vice-versa.
Compression
Ndb backup filesets can optionally be compressed using a parameter in the cluster configuration. Compression is performed by background IO threads in the data node processes, prior to writing data to disk. ndb_restore handles compressed backups automatically during restoration.
Encryption
From the 8.0.22 release, Ndb backup filesets can be encrypted. Backup encryption provides protection for data which must leave the cluster security perimeter, and combines with e.g. MySQL Binlog encryption to help implement a secure async replication mechanism. Backup encryption occurs in background IO threads in the data node processes.
Backups are encrypted and decrypted using a user supplied password. For each file in each backup fileset, a unique random salt value is generated, and combined with the password via a key derivation function to generate a symmetric encryption key for that file. The key is then used to encrypt the backup data using AES 256 CBC inline. For restoration, ndb_restore combines the user supplied password with the per-file salt values to determine the unique decryption key for each file.
Key = KDF(RandomSalt, Password)
EncryptedData = AES_256_CBC(Key, PlainData)
Using an external password in this way allows users to manage backup encryption secrets in alignment with existing policies and systems.
Backup and restore parallelism
Each Ndb backup runs in parallel across all data nodes, with each node producing independent filesets. At restore time, each ndb_restore instance restores batches of rows concurrently, and multiple ndb_restore instances can be run in parallel, each operating on independent backup filesets.
From the 8.0.16 release onwards, each data node can produce multiple backup filesets – one per Local Data Manager (LDM) component, and ndb_restore restores multiple backup filesets in parallel by default.
In the 8.0.20 release, the ability to use multiple ndb_restore instances to restore slices of a single backup fileset was added.
Triggering a backup
Users trigger a new Ndb backup using the management api (ndb_mgm / mgmapi). The command in the ndb_mgm shell (version 8.0.22) looks like this :
ndb_mgm > START BACKUP [<backup id>] [ENCRYPT PASSWORD='<password>’]
[SNAPSHOTSTART | SNAPSHOTEND] [NOWAIT | WAIT STARTED | WAIT COMPLETED]
The backup id affects the name of the backup files on disk. If no backup id is supplied, then the cluster generates one internally.
If an encryption password is supplied, then the generated backup files will be encrypted using this password. If the RequireEncryptedBackup parameter is set in the cluster configuration, then a password must always be supplied.
SnapshotStart and SnapshotEnd give some control over the choice of the transactionally consistent point in time that the backup represents – either at the start of the backup, before the backup is STARTED, or at the end of the backup, before the backup is COMPLETED. The default is SnapshotEnd, but SnapshotStart can be useful for coordinating the backup of an Ndb cluster with other clusters and external systems.
The NoWait, Wait Started and Wait Completed options affect when the START BACKUP command itself will return control to the user, with Wait Completed as the default.
Restoring a backup
The ndb_restore tool operates on one or more backup filesets generated by a node at backup time. The main options are :
- —restore-meta : Read the schema metadata from the backup and create the same schema in the target cluster.
- —restore-data : Read the backup data and log files, and use NdbApi to insert, update and delete data to restore to the backup consistency point.
Options can be combined, so that a single ndb_restore invocation performs multiple actions.
All backup filesets redundantly contain the schema metadata, but the –restore-meta step need only be performed once. This step will recreate the schema as it was at backup time, though in cases where the table distribution was not explicitly set, it will be automatically adjusted to suit the target cluster.
For the –restore-data step, the rows in the backup fileset’s DATA file are first inserted into the target cluster, then the entries from the backup fileset’s LOG file are idempotently applied to bring the target cluster to a transactionally consistent state.
For a SNAPSHOTEND backup, the backup log contains actions to redo, which are applied in the order they were logged.
For a SNAPSHOTSTART backup, the backup log contains actions to undo, which are applied in the reverse of the order that they were logged.
Where there are schema changes, or transformations applied, these are performed as data is restored. One exception is where type changes convert to/from/between BLOB types – in this case ndb_restore automatically uses internal staging tables to perform the restore in two steps.
ndb_restore can be used to restore data from backup filesets while a cluster is in operation, with some caveats :
- Data being restored is only consistent when the restore is complete, before which :
- Other clients can observe partially restored data
- Constraints may be temporarily violated
Some other relevant ndb_restore options :
-
—include-databases
Database(s) to include -
—exclude-databases
Database(s) to exclude -
—include-tables
Table(s) to include -
—exclude-tables
Table(s) to exclude -
—backup-password
Supply password used to encrypt the backup -
—disable-indexes
Temporarily disable all indexes and constraints described in the backup schema metadata -
—rebuild-indexes
Rebuild all disabled indexes and constraints described in the backup schema metadata -
—restore-epoch
Generate a pseudo row in the mysql.ndb_apply_status table containing the restore epoch of this backup -
—promote-attributes
Allow restore to target schema with wider types -
—lossy-conversions
Allow restore to target schema with narrower types -
—allow-pk-changes
Allow primary key differences in target schema -
—remap-column
Apply some data transforms during restore
The ndb_restore tool can also be used to show the content of backup filesets in various ways.
Restoration sequences
ndb_restore is a flexible tool. Full cluster restoration normally follows a sequence like this.
- Restore/create schema – serial
ndb_restore —restore-meta …
or some other means of creating a schema :
- Apply a mysqldump schema dump
- Execute a SQL script
- Use ndb_restore –restore-meta, then ALTER the tables
- …
Tables or databases can be included or excluded. - [ Drop indices and constraints – serial ]
ndb_restore —disable-indexes …
This step is only required if there are unique or foreign key constraints on the tables being restored.
Note that if the target cluster schema does not reflect the schema in the backup, then extra steps may be needed here to ensure all indices and constraints are disabled and rebuilt.
- Restore data – parallel/serial
ndb_restore —restore-data …
This step must be performed for each node which generated backup filesets, but these steps can be done serially or in parallel as they are independent to each other.Tables or databases can be included or excluded.
If the schema in the target cluster is different, then schema flexibility options may be required.
- [ Restore epoch – serial ]
ndb_restore —restore-epoch …
This step is only necessary when restoring a backup from another cluster which will act as an async replication source.
- [ Rebuild indices and constraints – serial ]
ndb_restore —rebuild-indexes …
This step is only necessary when indices and constraints have been disabled (step 2).
While the step itself must be run serially, internally it makes use of the parallelism of the cluster for fast index and constraint rebuilds.
For restoring a backup from a single data node cluster, with no schema changes, a single command can perform all of these steps in one pass :
ndb_restore –restore-meta –disable-indexes –restore-data –restore-epoch –rebuild-indexes …
However, it is more common that a backup has come from a multi node cluster, and requires a number of invocations of ndb_restore to fully restore. This enables efficient parallel restore independent of cluster scale.

{kind=link}