As enterprises grow and data and performance needs increase, purpose-built databases have become the new way to tackle specific data access patterns. Modeling and querying highly connected datasets on a traditional relational database can be performance intensive, and expressing relational-style queries against these datasets can be challenging. Graph databases like Amazon Neptune provide a new means for storing and querying highly connected datasets quickly and at massive scale.
To access the insights in your data using this technology, you first need to model the data as a graph. Often, the data exists across the enterprise in existing relational databases. Converting relational data structures to graph models can be complex and involve constructing and managing custom extract, transform, and load (ETL) pipelines. AWS Database Migration Service (AWS DMS) can manage this process efficiently and repeatably, whether you’re migrating a full application to Neptune or only copying a subset of your relational data for graph-specific use cases.
In this four-part series, we cover how to translate a relational data model to a graph data model using a small dataset containing airports and the air routes that connect them. Part one discussed the source data model and the motivation for moving to a graph model. Part two explored mapping our relational data model to a labeled property graph model. Part three covered the Resource Description Framework (RDF) data model. In this final post, we show how to use AWS DMS to copy data from our relational database to Neptune for both graph data models. You may wish to refer to the first three posts to review the source and target data models.
Putting it all together
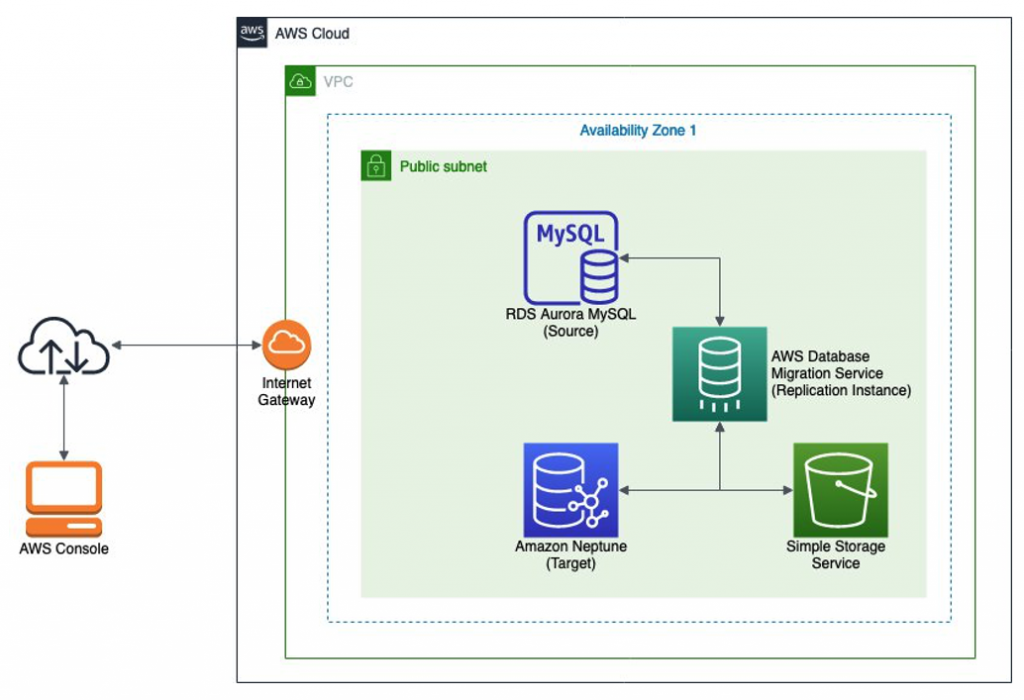
You can use AWS DMS to copy data from Oracle, Microsoft SQL Server, Azure SQL Database, SAP ASE, PostgreSQL, MySQL, and IBM Db2 LUW to Neptune. You can use several other non-relational sources as migration sources, but those are beyond the scope of this post. As depicted in the following architecture, you deploy AWS DMS via a replication instance within your VPC. You then create endpoints that the replication instance uses to connect to your source and destination databases. The source database, shown here within your VPC, can be on premises or hosted in the cloud. Connections to Neptune are only permitted from within its VPC, so you must deploy the AWS DMS replication instance in the same VPC as your target Neptune instance.

AWS DMS performs the following steps to migrate your relational data to Neptune:
- Copy the selected relational tables and views to the replication instance.
- Apply your graph mapping rules to produce a serialized graph model in the Amazon Simple Storage Service (Amazon S3) bucket you specified.
- If you’re creating a property graph, you create a graph mapping configuration file to drive the transformation, and AWS DMS builds edge and vertex comma-separated value (CSV) files on Amazon S3.
- If you’re creating an RDF graph, you create an R2RML file to drive the transformation, and AWS DMS builds an RDF file in N-QUADS format on Amazon S3.
- Trigger a bulk load of these files to efficiently load the data into your Neptune cluster.
To copy relational data to Neptune using AWS DMS, you complete the following steps:
- Create a Neptune cluster (if you haven’t already done so).
- Identify the source relational database to migrate to Neptune.
- Create a destination bucket on Amazon S3.
- Create an AWS DMS replication instance in the same VPC as Neptune.
- Define a target endpoint on your replication instance pointing to your Neptune cluster.
- Define a source endpoint on your replication instance pointing to your relational database.
- Define a new replication task on your replication instance using these mapping files.
- Specify task settings for the replication task.
- Create a table mapping that identifies the tables or views and columns that you migrate to Neptune, along with any transformations or filtering of that source data.
- Upload graph mapping rules (a JSON graph mapping configuration for property graph models or an R2RML file for RDF models) that map the selected tables or views and columns in your relational database to vertices, edges, and properties or triples.
- Initiate and monitor the replication task.
- Clean up your AWS DMS configuration when the task is complete.
Steps 1–3: Creating a cluster, identifying the source database, and creating a destination S3 bucket.
For this walkthrough, we assume that you already have a Neptune cluster created within a VPC. For instructions on creating a cluster, see Creating a New Neptune DB Cluster Using AWS CloudFormation or Manually.
We use a MySQL instance that we previously deployed and loaded with an open dataset that contains information on the world’s commercial airports and air routes.
We also assume that you have a destination bucket available on Amazon S3.
Step 4: Creating an AWS DMS replication instance
AWS DMS uses an Amazon Elastic Compute Cloud (Amazon EC2) instance to perform the data conversions as part of a given migration workflow. This EC2 instance is referred to as the replication instance. A replication instance is deployed within a VPC and has access to the source and target databases. To copy data to your Neptune cluster, you deploy the replication instance into the same VPC where your Neptune cluster is deployed.
You also need to make other considerations in terms of sizing your replication instance. For more information, see Choosing the optimum size for a replication instance
To deploy a replication instance, complete the following steps:
- Sign in to the AWS DMS console within the AWS account and Region where your Neptune cluster is located.
- In the navigation pane, under Resource management, choose Replication instances.
- Choose Create replication instance.

This brings you to the Create replication instance page.
- For Name, enter a name for your instance.
- For Description, enter a short description.
- For Instance class, choose your preferred instance. For this post, we use a c4.xlarge instance.
Charges may vary depending on your instance size, storage requirements, and certain data transfer usage. For more information, see AWS Database Migration Service Pricing.
- For Engine version, choose your AWS DMS version.
You need to specify a version of 3.3.2 or later so you can support replication to Neptune and define the correct VPC (the same VPC that your target cluster is using).
- Select if you want your instance to be publicly accessible.
If you’re migrating from a source that exists outside of your VPC, you need to select this option. If the source database is within your VPC, accessible over an AWS Direct Connect connection, or via a VPN tunnel to the VPC, you can leave this option deselected.

You can also define other options, such as specific subnets, Availability Zones, custom security groups, and if you want to use AWS Key Management Service (AWS KMS) encryption keys. For more information, see Working with an AWS DMS replication instance. For this post, we leave these options at their defaults.
- Choose Create.
Provisioning your replication instance may take a few minutes. Wait until provisioning is complete before proceeding to the next steps.
Step 5: Defining a Neptune target endpoint
After you provision a replication instance, you define both the source and targets for copying data. First, we define the connection to our target Neptune cluster. We do this by providing AWS DMS with a target endpoint configuration.
- On the AWS DMS console, under Resource management, choose Endpoints.
- Choose Create endpoint

This brings you to the Create endpoint page.
- For Endpoint type, select Target endpoint.
- For Endpoint Identifier, enter a name for your endpoint.
- For Server name, enter the cluster writer endpoint for your target Neptune cluster (available in the Neptune cluster details on the Neptune console).
- For Port, enter the port you use to connect to Neptune (the default is 8182).
- For IAM database authentication on Neptune¸ select Don’t use IAM database authentication.
- For Service access role’s Amazon Resource Name, enter the ARN for the service access role.
The ARN is available on the Roles page on the AWS Identity and Access Management (IAM) console.
- For S3 bucket folder path, enter the folder path for bulk loading.

Step 6: Defining an RDS source endpoint
We now define the source endpoint for your source RDBMS. The selections that follow reflect that our source relational database is an RDS Aurora MySQL instance.
- On the AWS DMS console, under Resource management, choose Endpoints.
- Choose Create endpoint.
- For Endpoint type¸ select Source endpoint.
- Select Select RDS DB Instance.
- For RDS Instance, choose your instance.
- For Endpoint Identifier, enter a name.
- For Source engine, choose aurora.
- For Server name, enter your source endpoint.
- For Port, enter 3306.
- For Secure Socket Layer, choose none.

Step 7: Defining a replication task
After you create the replication instance and source and target endpoints, you can define the replication task. At this point, you’ve also created a relational to graph mapping appropriate to your target graph type. To complete the replication task definition, complete the following steps:
- On the AWS DMS console, under Conversion & Migration, choose Database migration tasks.
- Choose Create database migration task.
- For Task identifier, enter your identifier.
- Choose your replication instance and source and target database endpoints.

Step 8: Configuring task settings for logging
After creating a task identifier, you can select task settings for logging and debugging.
- On the Task settings page, select Enable CloudWatch logs.
Amazon CloudWatch logs are useful if you encounter any issues when the replication task runs. You also need to provide IAM permissions for CloudWatch to write AWS DMS logs.
- Choose your values for Source Unload, Task Manager¸ Target Apply, Target Load, and Source Capture.
Initially, you may wish to keep the default values for logging levels. Later, if you encounter problems, you can modify the task to select more detailed logging information that can help you to troubleshoot.

Step 9: Creating a table mapping configuration
The table mapping configuration section of the replication task definition specifies the tables and columns that AWS DMS migrates to Neptune. You can specify the required information two different ways: using a guided UI or a JSON editor.

For this post, we select Guided UI.
The guided UI allows you to interactively select the tables that you migrate to your graph. You can also define this information in a JSON file that you can enter into the JSON editor. Using the guided UI creates the JSON file; you can save and reuse it when needed. For our use case, we use table include and exclude rules and drop several unused columns. See the following code:
For more information about sophisticated selection, filtering, and transformation possibilities, including table and view selection and using wildcards to select schemas, tables, and columns, see Using table mapping to specify task settings.
Step 10: Loading a relational to graph mapping file
As we discussed earlier, Neptune supports two different graph models: property graph and RDF. These models differ in both the modeling of the data and the mechanism for implementing the relational to graph mappings. You upload either the graph mapping configuration file or the R2RML file that we defined earlier, depending on which graph model you’re building on the target Neptune database.
You can define the graph mapping rules either by uploading a mapping file or entering text directly into a text editor. In most cases, you want to manage your configuration files, so it’s best to build your mappings first and upload the files. Refer to part two of this series to review the property graph mapping file, and part three to review the R2RML file.
For this post, we select Upload mapping file and upload our file.

Step 11: Starting the replication task
The definition of the replication task is now complete and you can start the task. The task status updates automatically as the process continues. When the task is complete, the status shows as Load Complete. If an error occurred, the error appears on the Overview details tab (see the following screenshot) under Last failure message.

For more information about troubleshooting, see Troubleshooting migration tasks in AWS Database Migration Service.
For our sample database, the AWS DMS process takes only a few minutes from start to finish.
Step 12: Cleaning up
When database migration is complete, you may wish to delete your replication instance. You can do this on the AWS DMS console, on the Replication instances page.

If you increased the size of the Neptune write primary instance to perform the migration, you may want to resize that back to the correct size for your typical operations. You can do this on the Neptune console.
Summary
AWS DMS can quickly get you started with Neptune and your own data.
This series discussed how to map relational data models to graph data models and use the power of Neptune to derive value from highly connected data. We used our air routes dataset to build a property graph model that enabled high-performance traversals to quickly calculate multi-stop air routes more quickly and intuitively than possible with relational models. We also built an RDF knowledge graph where we created new knowledge and insight using SPARQL 1.1 and DBpedia.
If you have any questions, comments, or other feedback, share your thoughts on the Amazon Neptune Discussion Forums.
About the author
 Chris Smith is a Principal Solutions Architect on the AWS Database Services Organization Customer Advisory Team focusing on Neptune. He works with customers to solve business problems using Amazon graph technologies. Semantic modeling, knowledge representation, and NLP are subjects of particular interest.
Chris Smith is a Principal Solutions Architect on the AWS Database Services Organization Customer Advisory Team focusing on Neptune. He works with customers to solve business problems using Amazon graph technologies. Semantic modeling, knowledge representation, and NLP are subjects of particular interest.
