Amazon DocumentDB (with MongoDB compatibility) is a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. You can use the same MongoDB application code, drivers, and tools to run, manage, and scale workloads on Amazon DocumentDB without worrying about managing the underlying infrastructure. As a document database, Amazon DocumentDB makes it easy to store, query, and index JSON data.
As use cases evolve, you may want to gain further insights from your data. For example, if you’re a social media platform, you might use Amazon DocumentDB to store user profiles and user content data modeled as JSON documents. As the platform grows, you want to search the user content to find patterns related to specific words. For example, you may want to determine which users post about sports, determine which users share content about dogs, or search data for specific tags. You can easily do this by running a full text query on the data. Amazon Elasticsearch Service (Amazon ES) is purpose-built to enable you to run full text search queries over your data.
In this post, we show you how to integrate Amazon DocumentDB with Amazon ES so you can run full text search queries over your Amazon DocumentDB data. Specifically, we show you how to use an AWS Lambda function to stream events from your Amazon DocumentDB cluster’s change stream to an Amazon ES domain so you can run full text search queries on the data. To automate the solution, we use Amazon EventBridge to trigger a message every 60 seconds to Amazon Simple Notification Service (Amazon SNS), which invokes the Lambda function on a schedule.
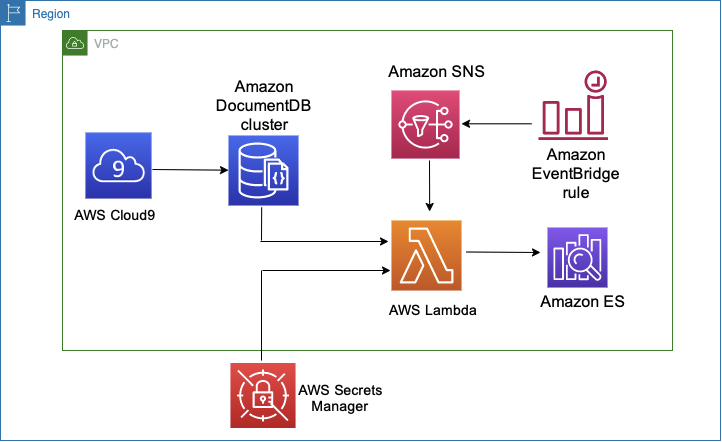
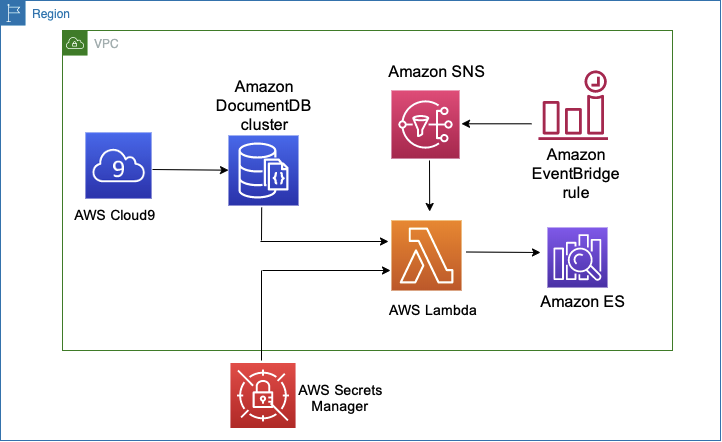
The following diagram shows the final architecture of this solution.
Walkthrough overview
This post includes the following tasks:
- Deploy an AWS CloudFormation template to launch the following:
- Amazon DocumentDB cluster
- Amazon ES domain
- AWS Cloud9 environment
- AWS Secrets Manager secret
- Amazon SNS trigger
- EventBridge rule
- Set up an AWS Cloud9 environment.
- Enable change streams on Amazon DocumentDB.
- Set up and deploy the Lambda streaming function that replicates change events from an Amazon DocumentDB cluster to Amazon ES domain.
- Run full text search queries.
Deploying a CloudFormation template
AWS CloudFormation provides a common language for you to model and provision AWS resources in your cloud environment. For this walkthrough, you deploy a CloudFormation template that creates the following:
- Amazon DocumentDB cluster – An operational data store for JSON data
- Amazon ES domain – To run full text search queries
- AWS Cloud9 environment – An integrated development environment (IDE)
- Secrets Manager secret – Manages Amazon DocumentDB credentials
- Amazon SNS trigger and EventBridge rule – Automates the solution and runs the Lambda function every 120 seconds
Note: This template will incur costs. For more information on pricing for the resources the template will deploy, see AWS pricing.
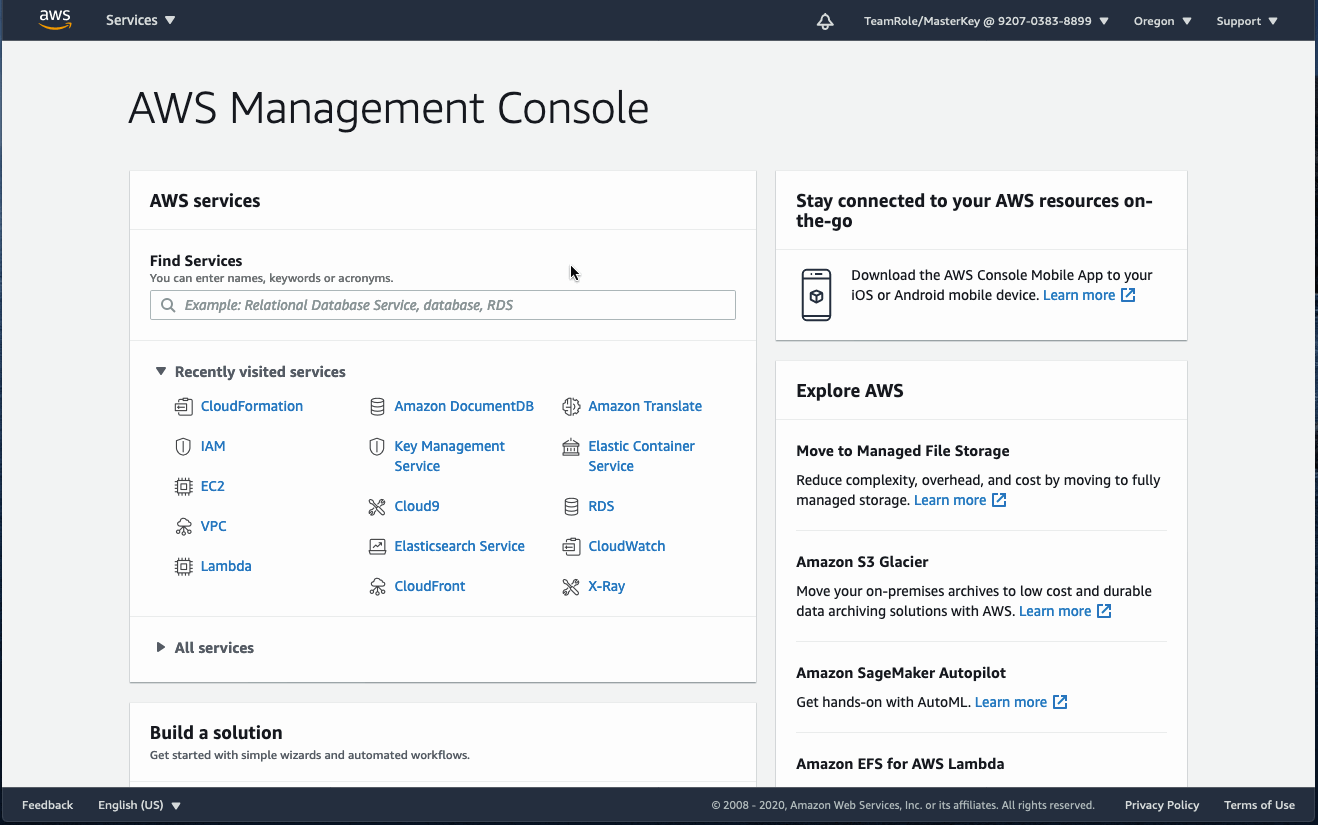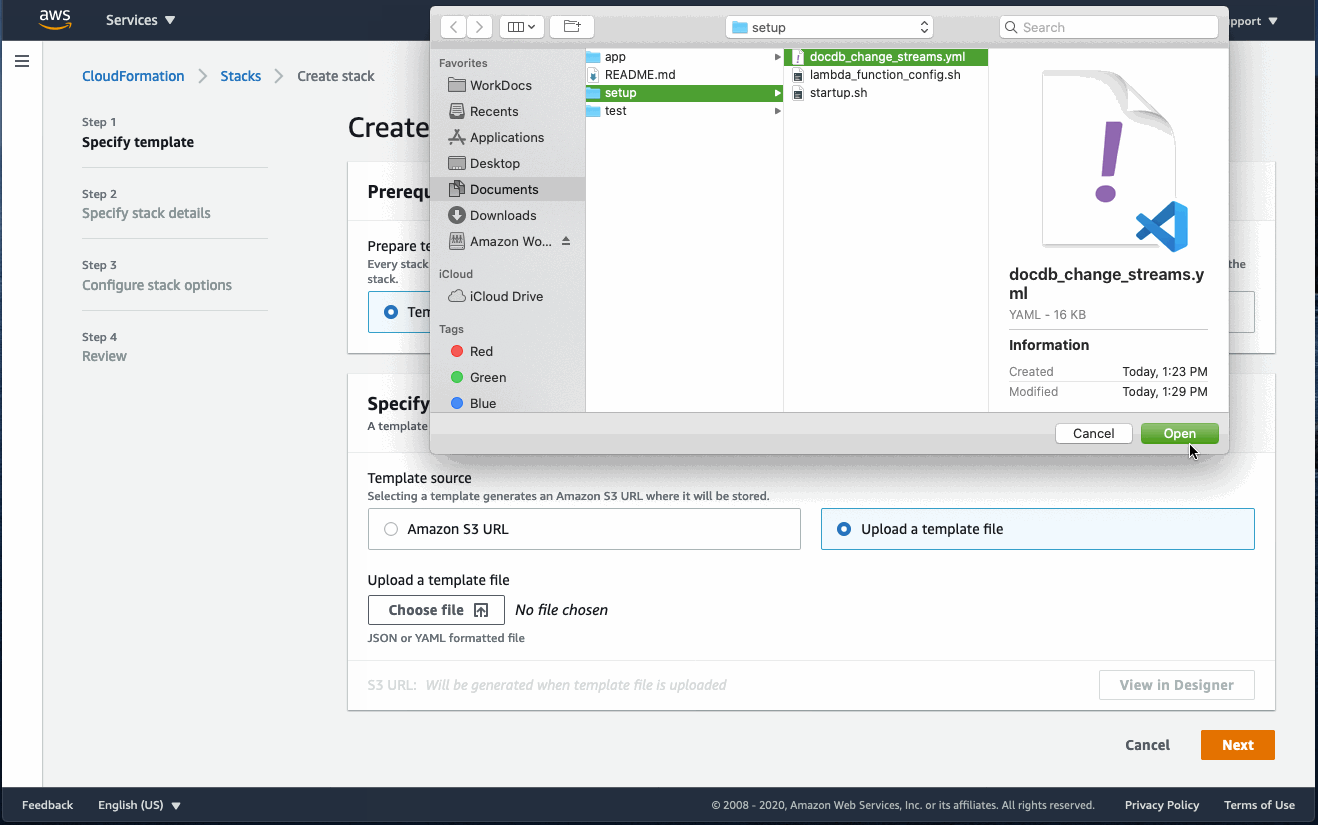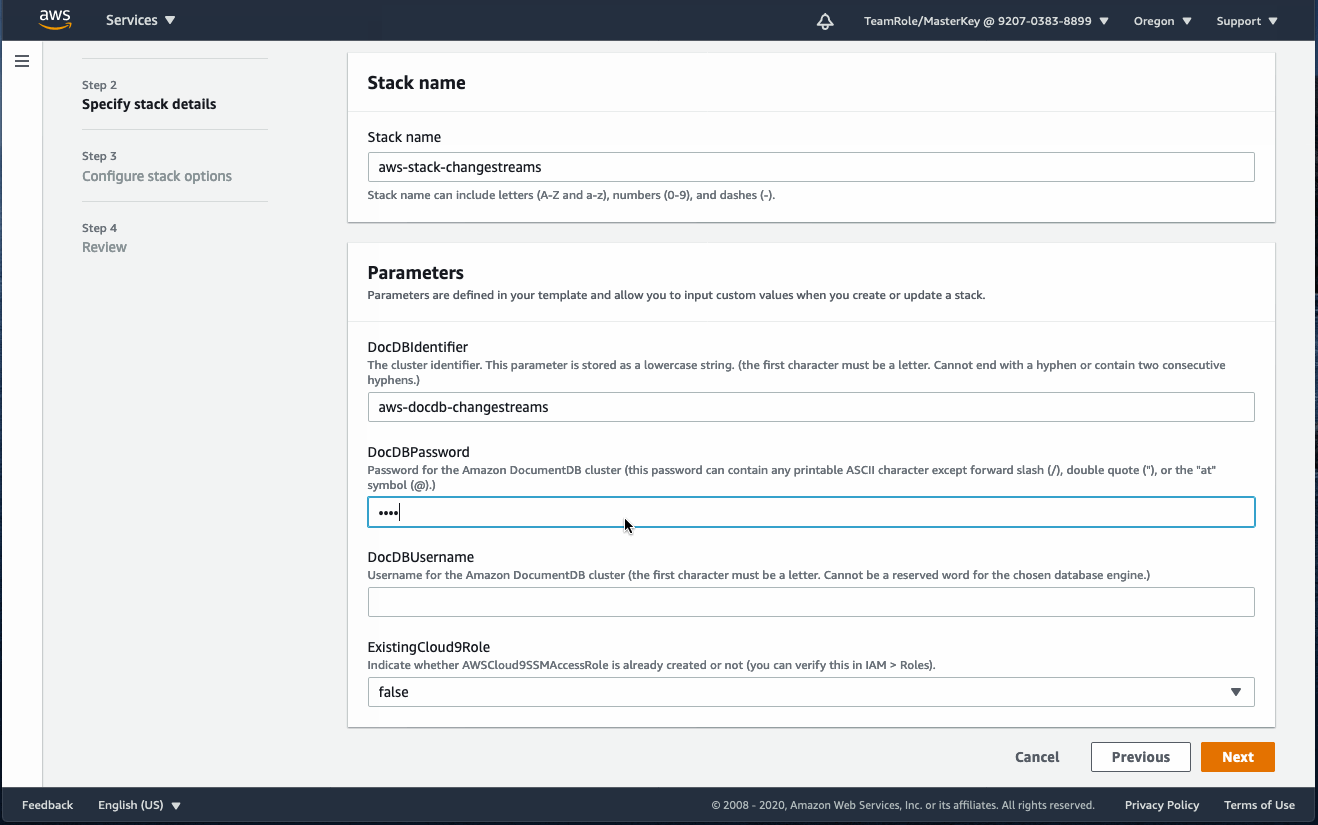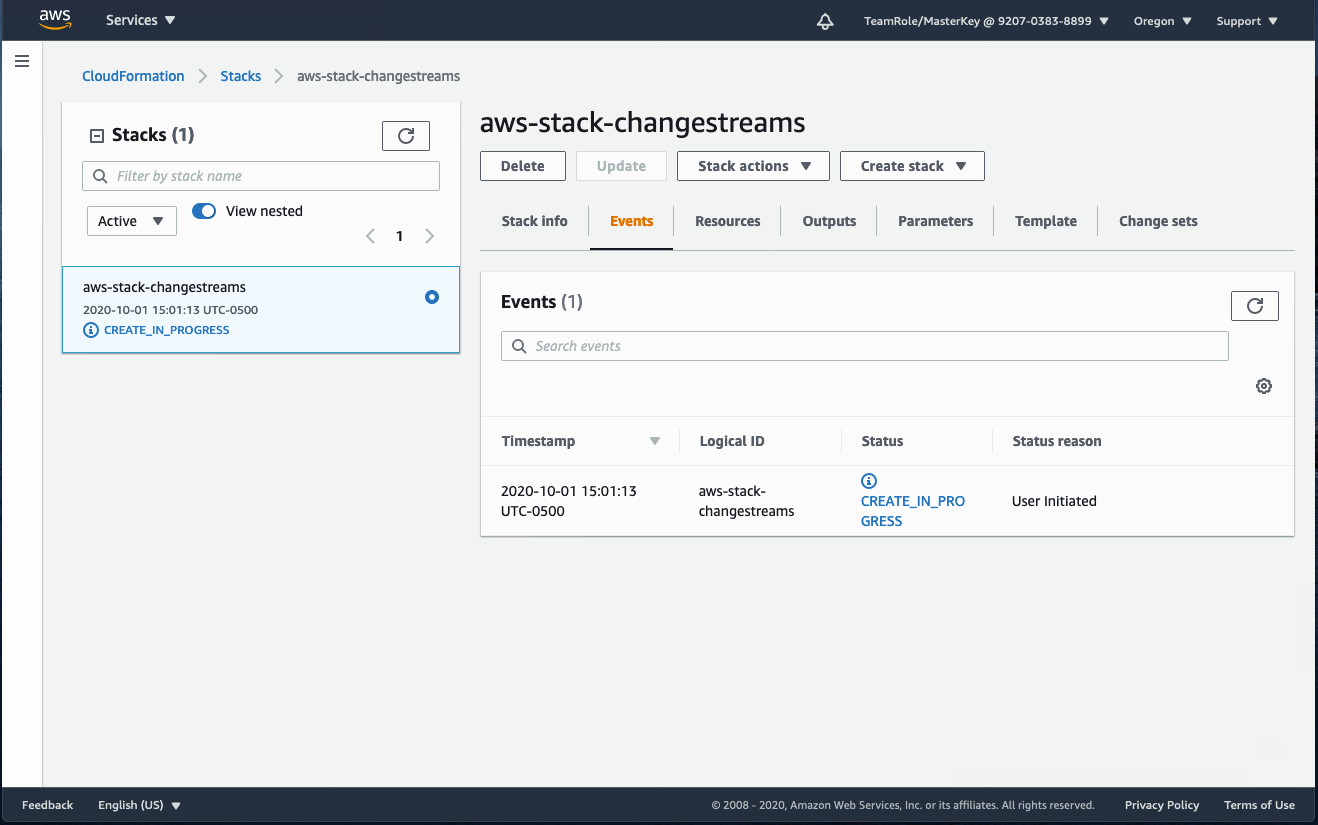
To deploy the template, complete the following steps:
- On the AWS CloudFormation console, choose Create stack.
- Choose Upload a template file.
- Choose Choose file.
- Upload the docdb_change_streams.yml file
- Choose Next.
- Enter a name, username, password, the identifier for your Amazon DocumentDB cluster.
AWS Cloud9 requires an AWS Identity and Access Management (IAM) role. If you have used AWS Cloud9 before, you should already have an existing role. You can verify by going to the IAM console and searching for the role AWSCloud9SSMAccessRole.
- If you already have this role, choose true. If not, choose false and the AWS CloudFormation template creates this role for you.
- Leave everything else at its default and choose Next.
- Select the check-box to allow the stack create a role.
- Choose Create stack.
The stack should complete provisioning in a few minutes.
Setting up an AWS Cloud9 environment
To set up your cloud-based IDE, complete the following steps:
- On the AWS Cloud9 console, launch the environment that was created with the CloudFormation stack.
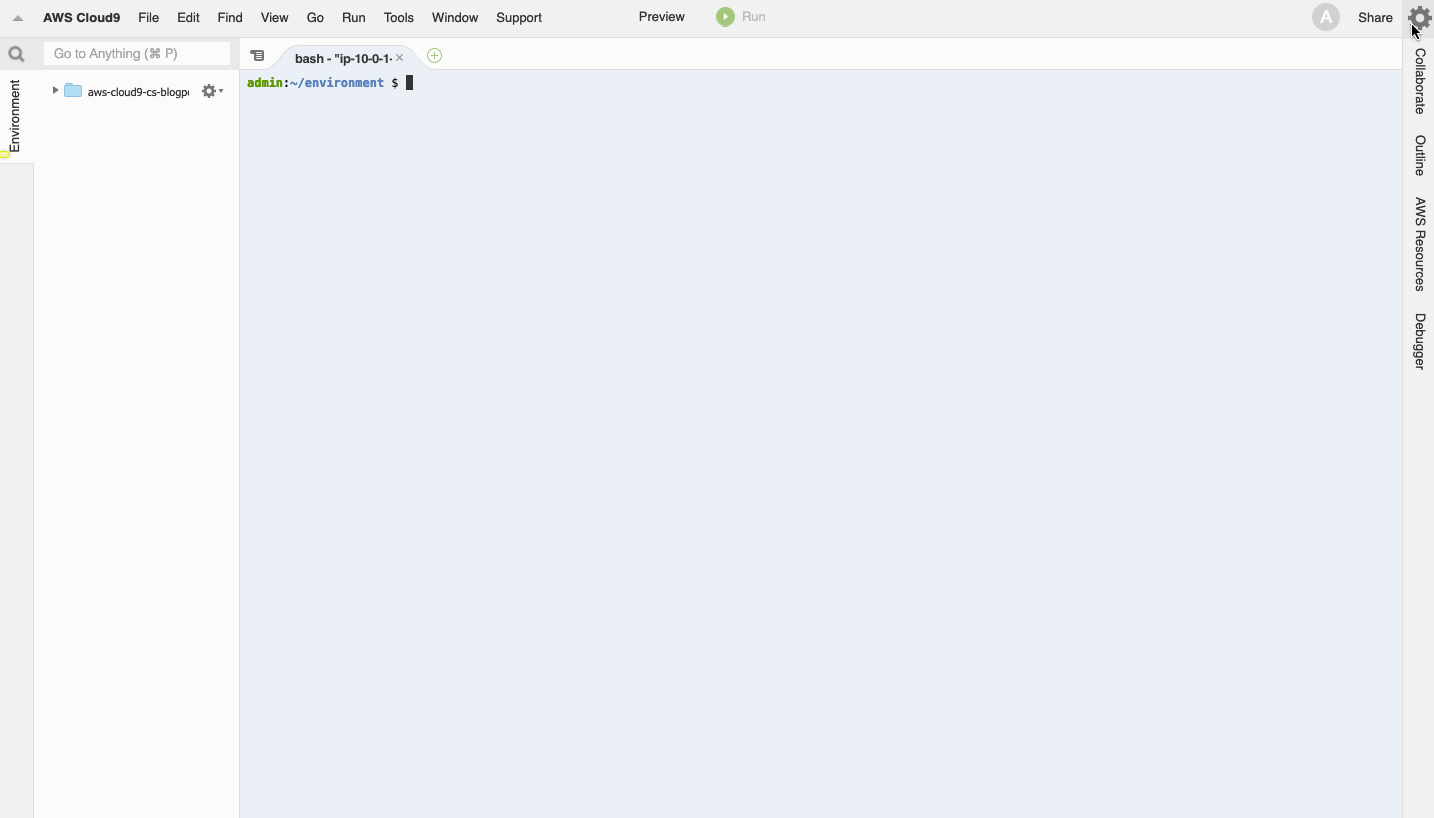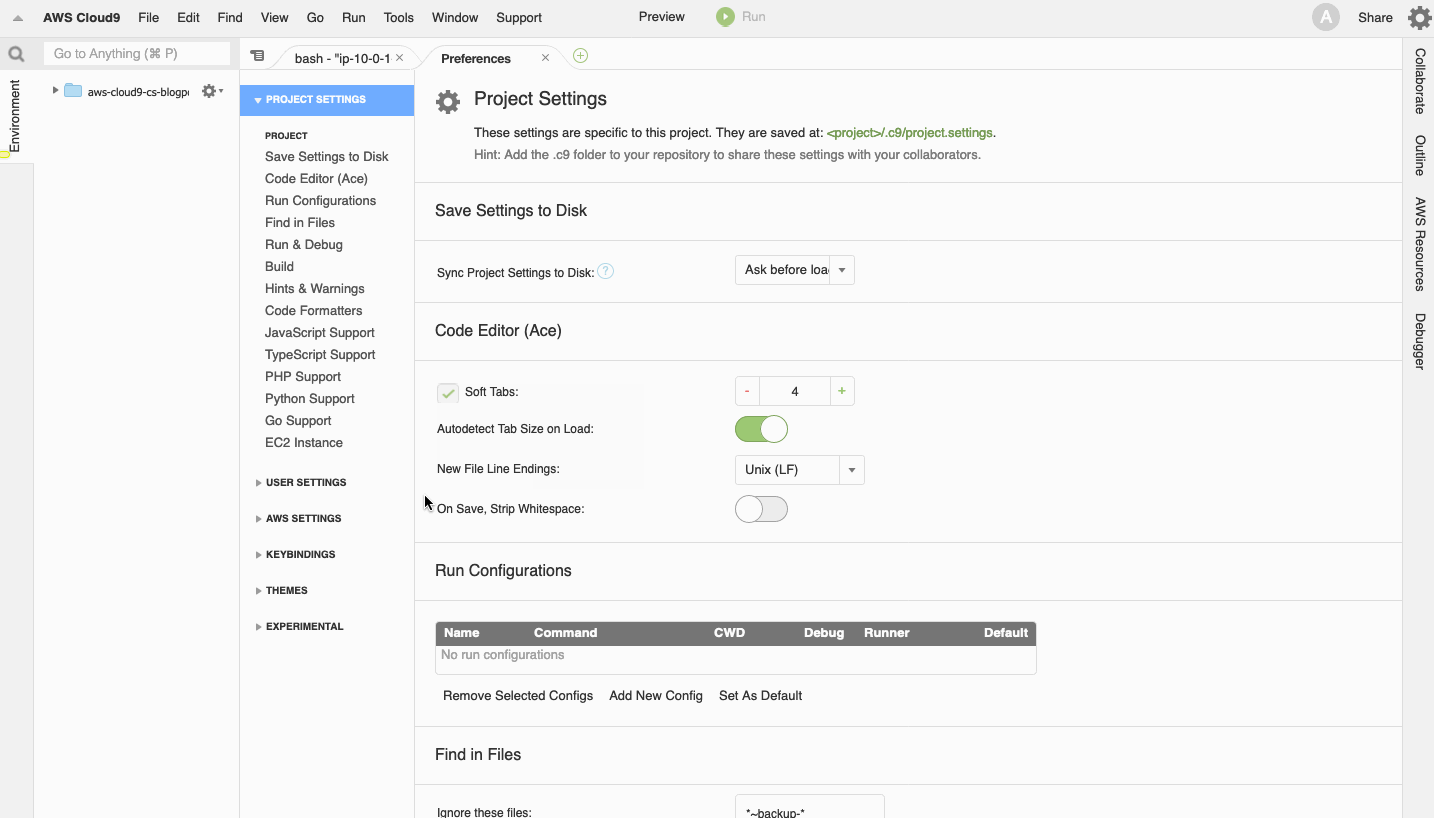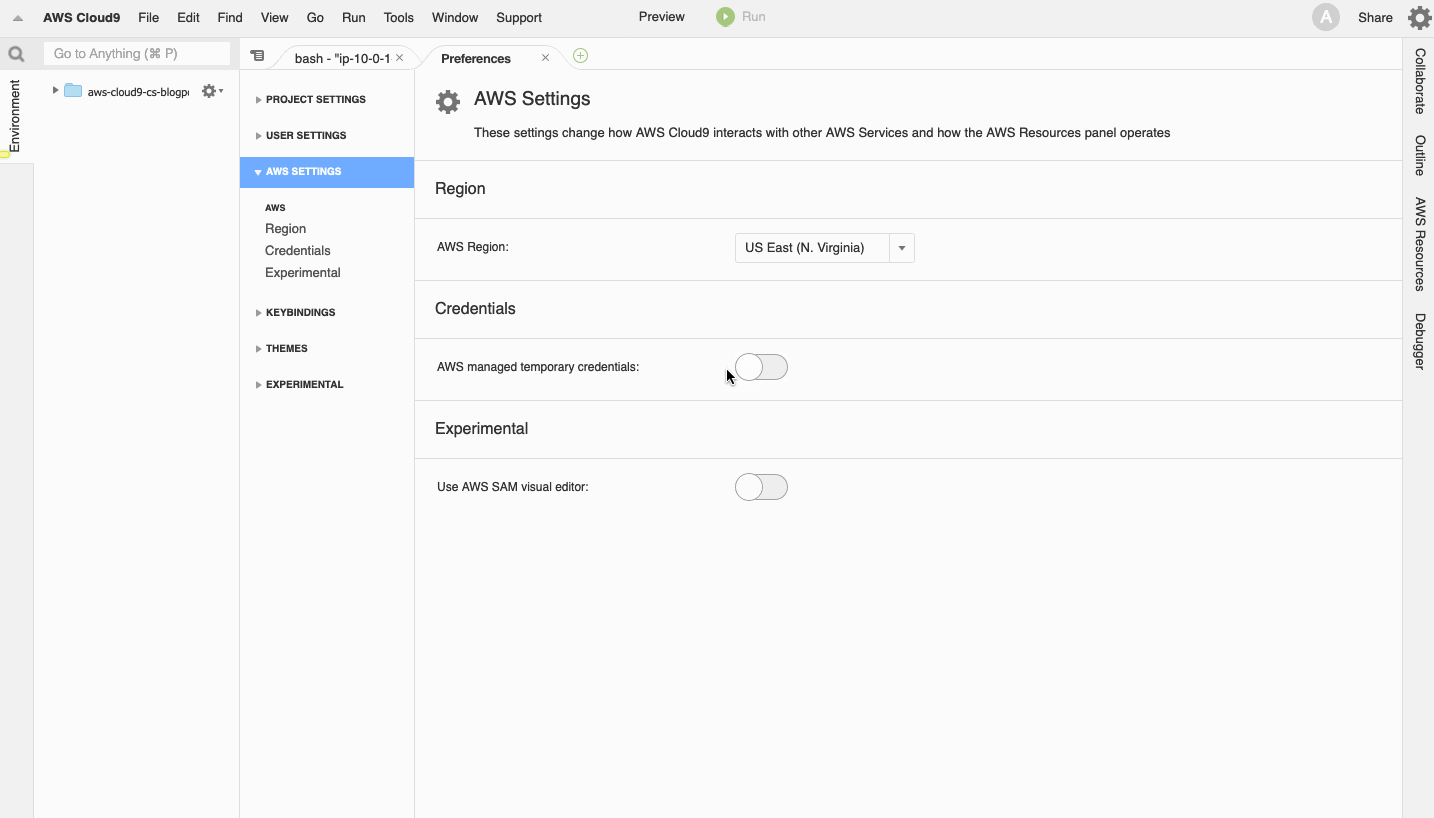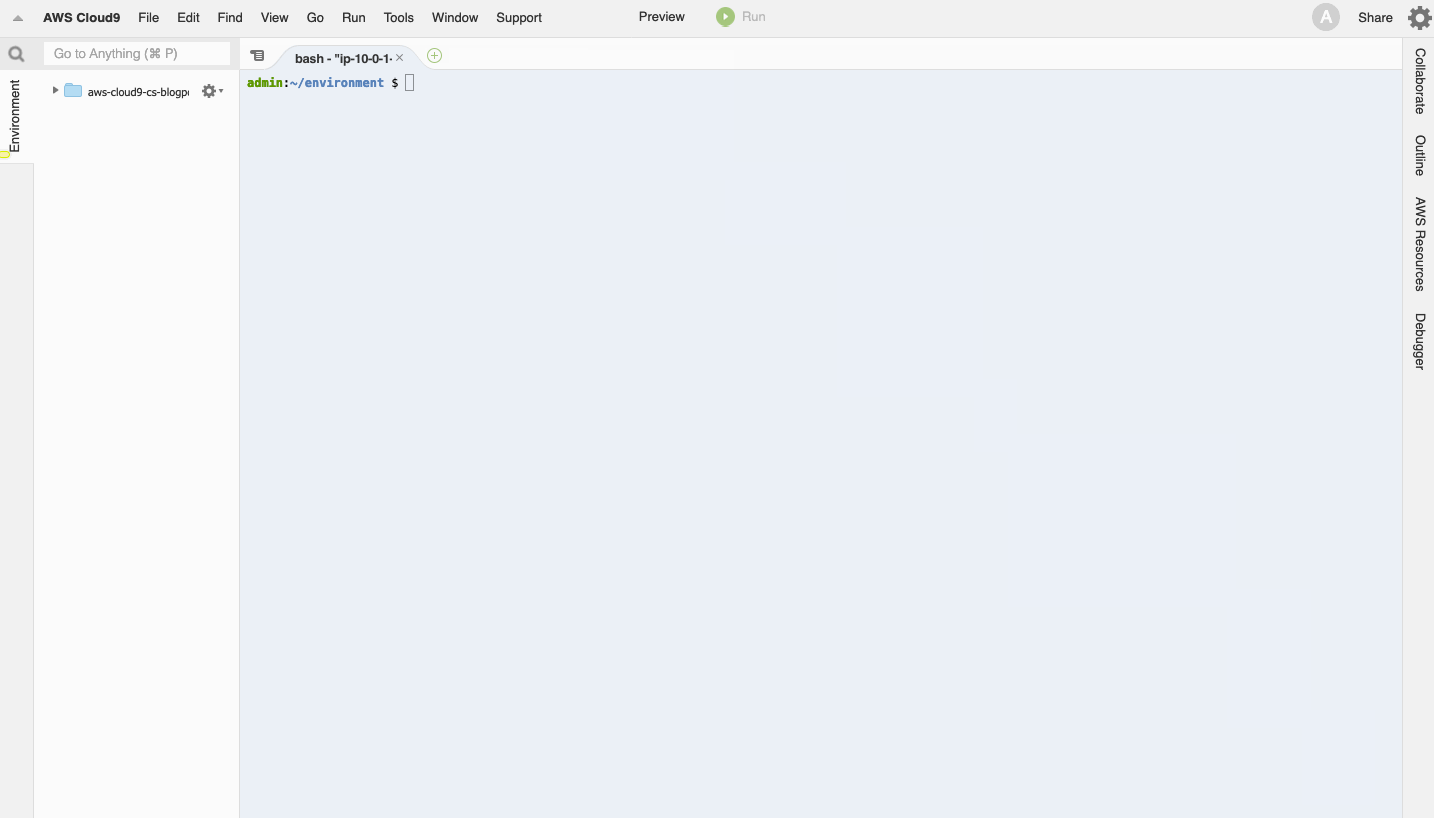
- From your environment, launch a new tab to open the Preferences tab.
- Choose AWS SETTINGS in the left navigation pane.
- Turn off AWS managed temporary credentials. This enables us to simplify the developer experience later in the walkthrough.
- Close the Preferences tab.
- From the terminal in your AWS Cloud9 environment, remove any existing credentials file with the following code:
- Create an environment variable for the CloudFormation stack name you created using the following code (we use this environment variable later):
- Configure the AWS Command Line Interface (AWS CLI) to use the current Region as the default:
- Download and run the startup.sh file by running the following code:
This startup script updates and installs the required Python libraries, packages the code for your Lambda function, uploads it to an Amazon Simple Storage Service (Amazon S3) bucket, and copies the output of the CloudFormation stack to the AWS Cloud9 environment.
Enabling change streams on Amazon DocumentDB
Amazon DocumentDB change streams provide a time-ordered sequence of update events that occur within your cluster’s collections and databases. You can poll change streams on individual collections and read change events (INSERTS, UPDATES, and DELETES) as they occur. We use change streams to stream change events from your Amazon DocumentDB cluster to an Amazon ES domain. To enable change streams on the cluster, enter the following code (replace with the values of your cluster). First, we use the mongo shell to log into the database:
Next, enable the change stream on your cluster:
You should get the following response:
Setting up and deploying the Lambda function
The Lambda function retrieves Amazon DocumentDB credentials from Secrets Manager, sets up a connection to the Amazon DocumentDB cluster, reads the change events from the Amazon DocumentDB change stream, and replicates them to an Amazon ES indexes. The function also stores a change stream resume token in the Amazon DocumentDB cluster so it knows where to resume on its next run. To automate the solution, we poll for changes every 60 seconds. We use EventBridge to trigger a message to Amazon SNS, which invokes the function.
The Lambda function uses three variables that you can tune:
- Timeout – The duration after which the Lambda function times out. The default is set to 120 seconds.
- Documents_per_run – The variable that controls how many documents to scan from the change stream with every function run. The default is set to 1000.
- Iterations_per_sync – The variable that determines how many iterations the Lambda function waits before syncing the resume token (the resume token to track the events processed in the change stream). The default is set to 15.
To deploy the Lambda function, open a new terminal in the AWS Cloud9 environment and enter the following code:
This creates and deploys a new CloudFormation stack. This stack provisions the Lambda function that streams change events from your Amazon DocumentDB cluster to an Amazon ES domain. The stack is populated with the following:
- Environment variables for the Amazon DocumentDB cluster
- Amazon ES domain
- Watched database name (the database that the Lambda function watches for change events)
- State database and collection name (the database and collection that stores the last processed change event)
- SNS topic ARN
- Lambda role ARN
- Secrets Manager ARN
Running full text search queries
Before you can start running full text search queries, complete the following steps:
- From your AWS Cloud9 terminal, enter the following code to insert sample data into your Amazon DocumentDB cluster. For the purposes of this walkthrough, we insert a few tweets from New Year’s Eve in 2014:
- Validate that documents were inserted by authenticating into your Amazon DocumentDB cluster from the mongo shell and using the following code:
After the data is inserted into your Amazon DocumentDB cluster, it’s automatically replicated to your Amazon ES domain when the Lambda function runs. The default trigger value runs your function every 120 seconds. This is set up using EventBridge and Amazon SNS. Alternatively, you can run the Lambda function via the AWS Management Console or the AWS CLI for one-time testing.
- After the Lambda function is triggered, validate the data has been replicated by entering the following code against your Amazon ES domain from the terminal in your AWS Cloud9 environment:
You should see that a new index was populated with the data from your Amazon DocumentDB cluster (see the following screenshot).

After the data is replicated to your Amazon ES domain, you can run full text search queries on your JSON data in the domain. For example, you can run a query to find all tweets that have some mention of “gym” in its text:
The following screenshot shows the expected output.

With Amazon ES, you can also run fuzzy full text search queries. Fuzzy queries return documents that contain terms similar to the search term. For example, if the search term is “hello,” documents with data matching “help,” “hallo,” “heloo,” and more are matched. In the following code, we run a query to find all tweets with text that has a fuzzy match for “New”:
The following screenshot shows the expected output.

For more information about types of Amazon ES queries, see Searching Data in Amazon Elasticsearch Service.
Cleaning up resources
To clean up the resources created in this post, navigate to the AWS CloudFormation console. Find the stacks you created for the walkthrough and delete them one by one. This should delete all resources associated with this walkthrough.
Summary
This post showed you how to integrate Amazon ES with Amazon DocumentDB to perform full text search queries over JSON data. Specifically, we used a Lambda function to replicate change events from an Amazon DocumentDB change stream to an Amazon ES index.
You can also use change streams to help integrate Amazon DocumentDB with other AWS services. For example, you can replicate change stream events to Amazon Managed Streaming for Apache Kafka (or any other Apache Kafka distro), Amazon Kinesis Data Streams, Amazon Simple Queue Service (Amazon SQS), and Amazon S3.
If you have any questions or comments about post, please share them in the comments. If you’re interested in looking at the source code for the Lambda function, have a suggestion, or want to file a bug, you can do so on our Amazon DocumentDB samples GitHub repo. If you have any feature requests for Amazon DocumentDB, email us at documentdb-feature-request@amazon.com.
About the authors
 Herbert Gomez is a Solutions Architect at Amazon Web Services. He works with AWS customers to help them architect secure, resilient, scalable and high performance applications in the Cloud.
Herbert Gomez is a Solutions Architect at Amazon Web Services. He works with AWS customers to help them architect secure, resilient, scalable and high performance applications in the Cloud.
 Vijay Injam is a Sr. NoSQL Data Architect at Amazon Web Services. His passion at AWS is to help customers innovate using AWS NoSQL databases.
Vijay Injam is a Sr. NoSQL Data Architect at Amazon Web Services. His passion at AWS is to help customers innovate using AWS NoSQL databases.
 Meet Bhagdev is a Senior Product Manager at Amazon Web Services. Meet is passionate about all things data and spends his time working with customers to understand their requirements and building delightful experiences. Prior to his time at AWS, Meet worked on Azure databases at Microsoft.
Meet Bhagdev is a Senior Product Manager at Amazon Web Services. Meet is passionate about all things data and spends his time working with customers to understand their requirements and building delightful experiences. Prior to his time at AWS, Meet worked on Azure databases at Microsoft.
