Customers often manage tree structures in their graph applications. Typical examples include categories of topics in a knowledge graph, relationships between people in an identity graph, or transaction networks in a financial application. Often, the structures are actually forests (collections of trees) with shared subtrees. In these applications, you frequently need to traverse a tree, deleting all the edges along the way, but not touch subtrees that are also linked from somewhere else in the graph. Deleting something that has dependencies, then deleting those, their dependencies, and so on, is called a cascading delete.
RDF graph databases such as Amazon Neptune don’t offer cascading delete as a feature, because you would need to understand how the data is modeled; thus, this is left to the application developer to implement. In this post, we show you how to write a cascading delete as a SPARQL query.
Example data
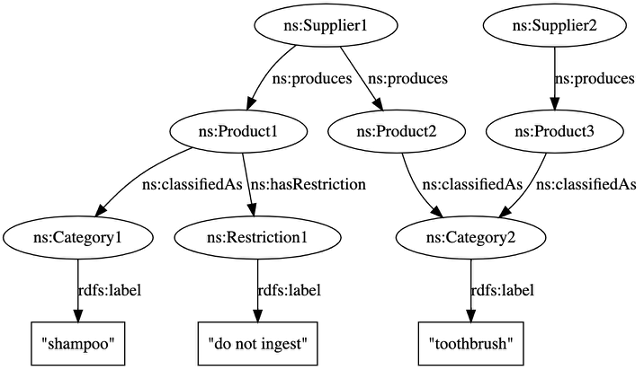
The test data for this post is a hypothetical small graph of product classifications: suppliers, products, product classifications, and product restrictions. Suppliers produce products, products are classified into categories, and are optionally associated with restrictions. See the following code:
The following diagram shows a visualization of the graph (ovals are called resources, and rectangles are literals).
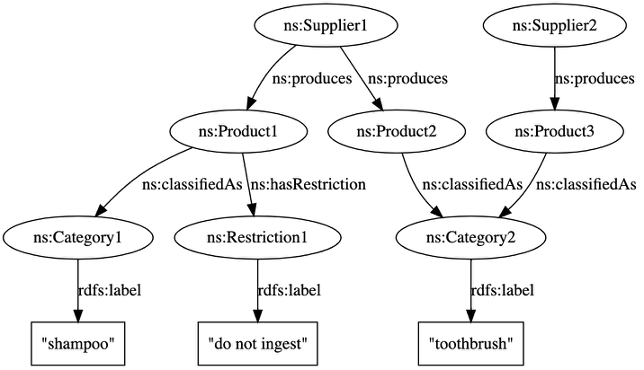
Use case
In this use case, we want to delete everything rooted in the supplier identified as ns:Supplier1, but not things also rooted in something else. To find all the nodes (RDF resources) rooted in ns:Supplier1, assuming we’re only interested in predicates ns:produces, ns:classifiedAs, and ns:hasRestriction, use the following SPARQL query:
If we run it on the test data, we get all the nodes except ns:Supplier2 and ns:Product3 (which is the expected output).
Next, we have to figure out how to get only those nodes that aren’t linked from somewhere else. We can do that by counting the inbound edges and filtering the result based on the count. See the following code:
We use an inner query because we need grouping (to use both regular variables and aggregate functions like count in your result, you need GROUP BY – see section 11.4 of the SPARQL 1.1 specification).
The inbound edge detection pattern is OPTIONAL, so that (in the case of our test data) we also include the root node, which doesn’t (or may not) have any inbound edges. We can still use a filter condition of count = 1 because we’re effectively counting how many times a particular node ends in the (inner query) solution, and in case of ns:Supplier1, with no inbound edges, it is still in the result set one time.
Final solution
To write the final cascading delete query, enter the following code:
In this query, the final basic graph pattern ?s ?p ?o finds all the triples rooted in the nodes we find on our walk down the tree.
Conclusion
You often need cascading delete when manipulating graph data, but SPARQL doesn’t have anything like this as a feature. In this post, we showed a simple example of how to implement a cascading delete, which you can adapt to your own data models. If you’re interested, you can launch a Neptune instance and use the Workbench to try this out.
About the Author
 Ora Lassila is a Principal Graph Technologist in the Amazon Neptune graph database group. He has a long experience with graphs, graph databases, ontologies, and knowledge representation, and was a co-author of the original RDF specification. He holds a PhD in Computer Science, but his daughters do not think he is a real doctor, the kind who helps people.
Ora Lassila is a Principal Graph Technologist in the Amazon Neptune graph database group. He has a long experience with graphs, graph databases, ontologies, and knowledge representation, and was a co-author of the original RDF specification. He holds a PhD in Computer Science, but his daughters do not think he is a real doctor, the kind who helps people.
