With Amazon RDS for SQL Server, you can quickly launch a database instance in just a few clicks and start serving your application requirements. Although Amazon RDS for SQL Server doesn’t typically require configuration changes, you may want to customize certain parameters based on your workload. This post discusses some parameters you can tune to enhance performance.
For example, you can change server-level parameters available under sp_configure using a custom parameter group. You customize database-level settings using SQL Server Management Studio (SSMS) GUI or T-SQL queries. In Amazon RDS, parameters can be either static or dynamic. A static parameter change needs an instance restart to take effect. Dynamic parameter changes take effect online without any restart and therefore can be changed on the fly.
In this post, we discuss the following configuration options to fine-tune performance:
- Maximum server memory
- Maximum degree of parallelism
- Cost threshold for parallelism
- Optimize for ad hoc workloads
- Configuring Tempdb
- Enabling autogrowth
- Updating statistics
We also discuss the steps to make these configuration changes in a custom parameter group.
Maximum server memory
SQL Server manages memory dynamically, freeing and adding memory as needed. Starting with SQL Server 2012 SingleMultipage allocations, CLR were all combined under Any Page Allocator and the maximum memory allocated to these is controlled by max server memory.
After SQL Server is started, it slowly takes the memory specified under min server memory (MB) and continues to grow until it reaches the value specified in max server memory (MB). SQL Server memory is divided into two parts: buffer pool and non-buffer pool, or Mem To Leave (MTL). The value of max server memory determines the size of the SQL Server buffer pool. A buffer pool consists of various caches such as buffer cache, procedure cache, and plan cache.
Starting with SQL Server 2012, max server memory accounts for all memory allocations for all caches (such as SQLGENERAL, SQLBUFFERPOOL, SQLQUERYCOMPILE, SQLQUERYPLAN, SQLQUERYEXEC, SQLOPTIMIZER, and SQLCLR). For a complete list of memory clerks under max server memory, see sys.dm_os_memory_clerks.
You can calculate the total memory SQL Server 2012 or above uses as follows:
Total memory used by SQL Server = max server memory + DLLs loaded into SQL Server memory space) + (2 MB (for 64 bit) * max worker threads)
The objective behind a buffer pool is to minimize the disk I/O. You use a buffer pool as the cache, and max_server_memory controls its size. The target of buffer pool is not to become so big that the entire system runs low on memory and minimize disk I/O.
The non-buffer pool or MTL comprises mainly of thread stacks, third-party drivers, and DLLs. SQL Server (on 64 bit) takes 2 MB of stack memory for each thread it creates. This thread stack memory is placed outside of max server memory or buffer pool and is part of non-buffer pool.
To find the total server memory, use the below query:
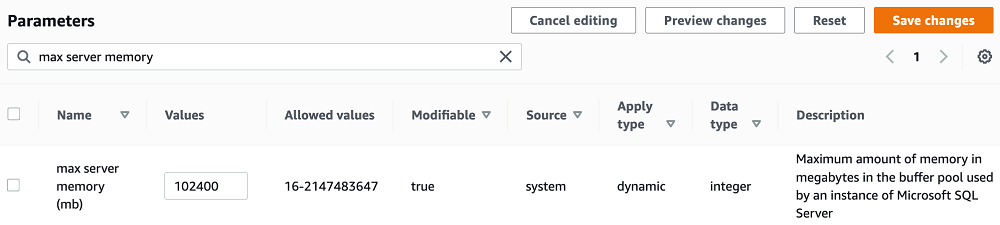
To change the maximum server memory in Amazon RDS for SQL Server, you can use a custom parameter group. In the following screenshot, I change the maximum server memory to 100 GB.
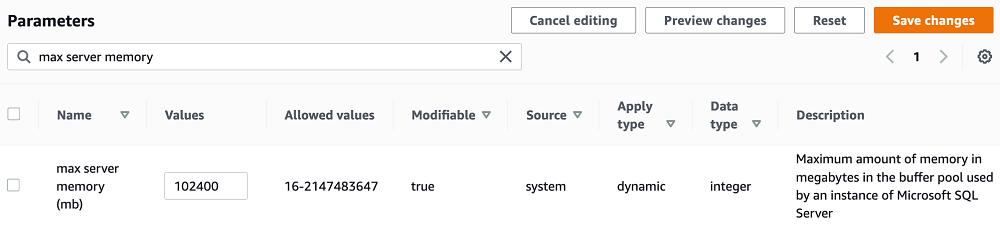
The idea is to cap max server memory to a value that doesn’t cause system-wide memory pressure. However, there’s no universal formula that applies to all the environments. You can use the following guidelines as a starting point:
Max server memory = Total RAM on the system – ((1 – 4 GB for the Operating System) + (MTL (includes stack size (2 MB) * max worker threads))
Note: Some of the exceptions to the above method of calculation will be t2/t3 kind of lower sized instances, be cautious when configuring max server memory on the same.
For further details please refer to Server memory configuration options.
After initial configuration, monitor the freeable memory over a typical workload duration to determine if you need to increase or decrease the memory allocated to SQL Server.
When using SSIS, SSAS, or SSRS, you should also consider the memory usage by those components when configuring max server memory in SQL Server.
You can configure the value under a custom parameter group. To check the current value, use the below query:
Monitoring
When using the Amazon RDS Performance Insights dashboard, you can monitor the following:
- physAvailKb – The amount of physical memory available in KB
- sqlServerTotKb – The amount of memory committed to SQL Server in KB
For more information, see Performance Insights is Generally Available on Amazon RDS for SQL Server.
When to change the configuration
You should change the configuration based on monitoring in your environment. Select the metrics to monitor on the Performance Insights dashboard, under OS metrics.

Maximum degree of parallelism (MAXDOP)
In an OLTP environment, with high core, hyperthreaded machines being a norm these days, you should pay special attention to max degree of parallelism. Running with the default configuration can lead to severe parallelism-related wait time, severely impair performance, and in extreme cases, bring the server down. A runaway query can lead to server-wide blocking due to parallelism-related wait times. A runaway query example here could be a query going for a parallel plan and spending a lot of time waiting on operations of parallel threads to complete. Such queries typically spend a long time waiting on CXPACKET.
A maximum degree of parallelism controls the number of processors used to run a single statement that has a parallel plan for running. The default value is set to 0, which allows you to use the maximum available processors on the machine.
With SQL Server 2016 and above, if more than eight physical cores per NUMA node or socket are detected at startup, soft NUMA nodes are created automatically. Starting with SQL Server 2016 (13.x), use the following guidelines when you configure the maximum degree of parallelism server value:
- Single NUMA node: < = 8 logical processors, keep MAXDOP <= actual number of cores
- Single NUMA node: > 8 logical processors, keep MAXDOP = 8
- Multiple NUMA nodes: < =16 logical processors, keep MAXDOP <= actual number of cores
- Multiple NUMA nodes: > 16 logical processors, keep MAXDOP = 16 (SQL Server 2016 and above), keep MAXDOP = 8 (prior to SQL Server 2016)
For more information, see Configure the max degree of parallelism Server Configuration Option.
SQL Server estimates how costly a query is when run. If this cost exceeds the cost threshold of parallelism, SQL Server considers parallel plan for this query. The number of processors it can use is defined by the instance-level maximum degree of parallelism, which is superseded by the database-level maximum degree of parallelism, which in turn is superseded by the query hint for maximum degree of parallelism at the query level.
To gather the current NUMA configuration for SQL Server 2016 and higher, run the following query:
You can configure the max_degree_of_parallelism value under a custom parameter group. In the following screenshot, I change the value to 4.
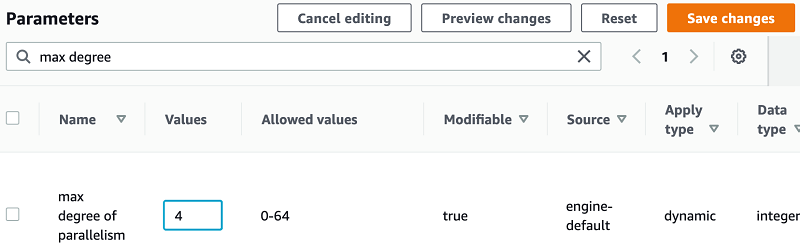
You can check the current value using the following query:
Monitoring
You can use the sys.dm_os_wait_stats DMV to capture details on the most common wait types encountered in your environment. On the Performance Insights dashboard, you can slice by waitypes to get details on top wait types as shown below:
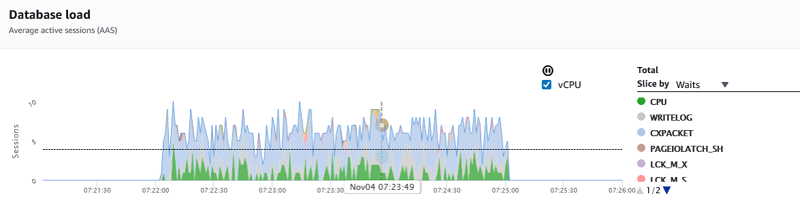
If you see an increase in these metrics and parallelism-related wait types (such as CXPACKET), you might want to revisit the max degree of parallelism setting.
When to change the configuration
When the server has more than eight cores and you observe parallelism-related wait types, you should change this value according to best practices, monitor the wait types, and adjust further if needed. You can monitor the wait types using the methods outlined earlier in this section. Typically, for several short-lived, repetitive queries (OLTP), a lower MAXDOP setting works well because you can lose a lot of time with higher MAXDOP for synchronization of threads running subtasks. For OLAP workloads (longer and fewer queries), a higher maximum degree of parallelism can give better results because the query can use more cores to complete the work quickly.
You can also set max degree of parallelism at the database level, starting at SQL Server 2014 SP2. The database-level setting overwrites the server-level configuration. Similarly, you can use a query hint specifying MAXDOP to override both the preceding settings.
Cost threshold for parallelism
The cost threshold for parallelism parameter determines the times at which SQL Server creates and runs parallel plans for queries. A parallel plan for a query only runs when the estimated cost of the serial plan for that query exceeds the value specified in the cost threshold for parallelism.
The default value for this parameter is 5. Historically, the default value was 5 because processors had exorbitant price tags and processing power was low, therefore query processing was slower. Processors today are much faster. Comparatively smaller queries (for example, the cost of 32) don’t see much improvement with a parallel run, not to mention the overhead with coordination of a parallel run.
With several queries going for a parallel plan, you may end up in a scenario with wait types like scheduler yield, threadpool, and parallelism related.
You can configure the cost threshold for parallelism value under a custom parameter group. In the following screenshot, I change the value to 50 for 64 core environment.
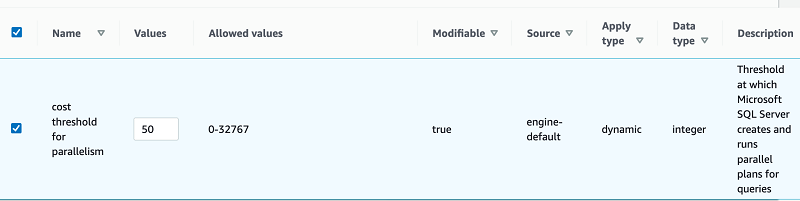
You can change this parameter using custom parameter group. To check the current value, use the below query:
For more details on this configuration please refer to Configure the cost threshold for parallelism Server Configuration Option.
Monitoring
In the Performance Insights monitor CXPACKET wait events. If this is on higher side you may want to increase cost threshold of parallelism as described above. You may refer the Performance Insights screenshot under the section “maximum degree of parallelism.”
When to change the configuration
On modern machines, 50 is an acceptable value to start with.
Optimize for ad hoc workloads
To improve plan cache efficiency, configure optimize for ad hoc workloads. This works by only caching a compiled plan stub instead of a complete run plan on the first time you run an ad hoc query, thereby saving space in the plan cache. If the ad hoc batch runs again, the compile plan stub helps recognize the same and replaces the compiled plan stub with the full compiled plan in the plan cache.
To find the number of single-use cached plans, enter the following query:
You can check the size of a stub and the plan of a query by running a query at least twice and checking the size in plan cache using a query similar to the following query:
You can configure the optimize_for_ad_hoc_workloads value under a custom parameter group. In the following screenshot, I set the value to 1.
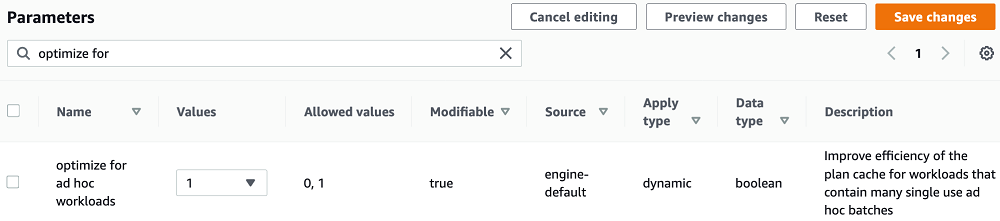
You can change this value in custom parameter group. To check the current value, run the below query:
For more details please refer optimize for ad hoc workloads Server Configuration Option.
Monitoring
In addition to the preceding query, you can check the number of ad hoc queries on the Performance Insights dashboard by comparing the following:
- Batch requests – Number of Transact-SQL command batches received per second.
- SQL compilations – Number of SQL compilations per second. This indicates the number of times the compile code path is entered. It includes compiles caused by statement-level recompilations in SQL Server.
When to change the configuration
If your workload has many single-use ad hoc queries, it’s recommended to enable this parameter.
Configuring tempdb
On a busy database server that frequently uses tempdb, you may notice severe blocking when the server is experiencing a heavy load. You may sometimes notice the tasks are waiting for tempdb resources. The wait resources are pages in tempdb. These pages might be of the format 2:x:x, and therefore on the PFS and SGAM pages in tempdb.
To improve the concurrency of tempdb, increase the number of data files to maximize disk bandwidth and reduce contention in allocation structures. You can start with the following guidelines:
- If the number of logical processors <=8, use the same number of data files as logical processors
- If the number of logical processors > 8, use eight data files
On RDS for SQL Server 2017 or below we have a single tempdb file by default.
If contention persists, increase the number of data files in multiples of 4 until the contention is remediated, maximum up to the number of logical processors on the server. You may refer the below article for more details
Recommendations to reduce allocation contention in SQL Server tempdb database
You add multiple tempdb files because the Amazon RDS primary account has been granted the control permission on tempdb.
The following query creates and modifies four files with parameters SIZE = 8MB, FILEGROWTH = 10% (you should choose parameters best suited for your environment):
You can use sp_helpdb 'tempdb' to verify the changes.
Note: For Multi AZ setup, please remember to make this change on the DR as well.
When you create multiple files, you may still want to maintain the total size of the tempdb equal to what it was with a single file. In such cases, you need to shrink a tempdb file to achieve the desired size. To shrink the tempdev file, enter the following code:
To shrink a templog file, enter the following code:
Following the tempdev shrink command, you can alter the tempdev file and set the size as per your requirement.
When initial pages are created for a table or index, the MIXED_PAGE_ALLOCATION setting controls whether mixed extent can be used for a database or not. When set to OFF it forces page allocations on uniform extents instead of mixed extents, reducing contention on the SGAM page.
Starting with SQL Server 2016 (13.x) this behavior is controlled by the SET MIXED_PAGE_ALLOCATION option of ALTER DATABASE. For example, use the following query to turn it off:
AUTOGROW_ALL_FILES determines that, when a file needs to grow in a file group, all the files in the file group grow with the same increment size.
Starting with SQL Server 2016 (13.x), this behavior is controlled by the AUTOGROW_SINGLE_FILE and AUTOGROW_ALL_FILES option of ALTER DATABASE, you may use the following query to enable AUTOGROW_ALL_FILES:
Monitoring
You want to monitor for wait types on tempdb, such as PAGELATCH. You may monitor this via Performance Insights (PI), as per the screenshot above, under the section “Maximum degree of parallelism.”
When to change the configuration
When wait resources are like 2:x:x, you want to revisit the tempdb configuration.
To check the wait resource in tempdb, use the following query:
Updating the statistics
If the optimizer doesn’t have up-to-date information about the distribution of key values (statistics) of table columns, it can’t generate optimal run plans. Update the statistics for all the tables regularly; the frequency of the update statistics depends on the rate at which the database handles DML operations.
For more information, see UPDATE STATISTICS. Please note that the update statistics works at one table at a time. sp_updatestats which is a database level command is not available in RDS. You may either write a cursor using update statistics to update statistics on all the objects in a database or you may build a wrapper around sp_updatestats.
Please refer the below workaround to use a wrapper around sp_updatestats:
Creating a custom parameter group in Amazon RDS for SQL Server
To make these configuration changes, first determine the custom DB parameter group you want to use. You can create a new DB parameter group or use an existing one. If you want to use an existing custom parameter group, skip to the next step.
Creating a new parameter group
To create a new parameter group, complete the following steps:
- On the Amazon RDS console, choose Parameter groups.
- Choose Create parameter group.
- For the parameter group family, choose the applicable family from the drop-down menu (for example, for SQL Server 2012 Standard Edition, choose sqlserver-se-11.0).
- Enter a name and description.
- Choose Create.
For more information, see Creating a DB Parameter Group.
Modifying the parameter group
To modify your parameter group, complete the following steps:
- On the Amazon RDS console, choose Parameter Groups.
- Choose the parameter group you created (or an existing one).
- Choose Edit parameters.
- Search for the parameter you want to modify (for example,
max_server_memory,max_degree_of_parallelism, oroptimize_for_ad_hoc_workloads). - Change the value as needed.
- Choose Save.
Repeat these steps for each parameter you want to change.
For more information, see Modifying Parameters in a DB Parameter Group.
Attaching the custom parameter group to your instance
To attach the parameter group to your instance, complete the following steps:
- On the Amazon RDS console, choose the instance you want to attach the DB parameter group to.
- On the Instance Actions tab, choose Modify.
- On the Modify instance page, under Database Options, from the DB parameter group drop-down menu, choose your custom parameter group.
- Choose Continue.
- On the next page, select Apply immediately.
- Choose Continue.
- Choose Modify DB instance.
Restarting the DB instance
For the changes to take effect, you need to restart the DB instance.
- On the Amazon RDS console, choose Instance.
- Choose your instance.
- Under Instance details, you should see the parameter group you’re applying.
- When the status changes to
Pending reboot(this may take a few minutes), under Instance actions, choose Reboot.
Checking the parameter group is attached
To confirm that the parameter group is attached to your instance, complete the following steps:
- On the Amazon RDS console, choose the instance you want to check the parameter group for.
- On the Details tab, look at the value for Parameter Group.
Verifying the configuration changes
To verify the configuration changes, complete the following steps:
- Connect to your Amazon RDS for SQL Server instance using your primary user account.
- Run the following to verify the configuration changes:
# sp_configure
Conclusion
This post discussed how to fine-tune some parameters in Amazon RDS for SQL Server to improve the performance of critical database systems. The recommended values are applicable to most environments; however, you can tune them further to fit your specific workloads. We recommend changing one or two parameters at a time and monitoring them to see the impact.
About the Author

Abhishek Soni is a Partner Solutions Architect at AWS. He works with the customers to provide technical guidance for best outcome of workloads on AWS. He is passionate about Databases and Analytics.
