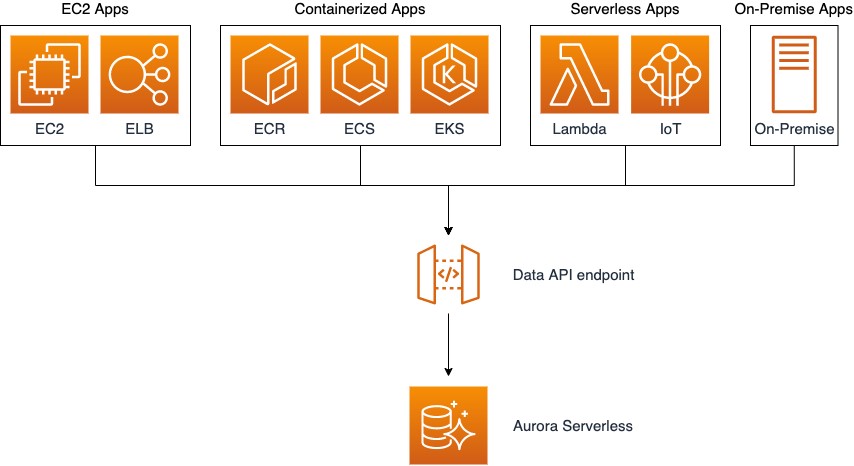
Amazon Aurora Serverless is an on-demand, autoscaling configuration for Amazon Aurora, where the database automatically starts up, shuts down, and scales capacity up or down based on your application’s needs. It enables you to run your database in the cloud without provisioning or managing any database instances, so you can focus on building and innovating.
Aurora Serverless is suitable for workloads that have intermittent, infrequent, or unpredictable bursts of requests. Some examples are development and test databases that are infrequently used, ecommerce applications occasionally running flash sales, or new applications you can’t predict capacity for. Arranging to have just the right amount of capacity for these workloads can be a lot of work; paying for it on a steady-state basis might not be sensible.
With Aurora Serverless, you should be mindful of a few things, such as connection management and cold starts. In this post, we describe some of the important best practices for Aurora Serverless such as operational debugging tools, security, and monitoring.
Connection management
One key challenge for modern serverless applications is connection management. An application communicates with a database by establishing connections. Establishing such a connection consumes valuable compute and memory resources on the database server. Serverless applications can open a large number of database connections or frequently open and close connections. This can have a negative impact on the database and lead to slower performance. The capacity allocated to your Aurora Serverless DB cluster seamlessly scales up and down based on the load (the CPU utilization and the number of connections) generated by your application. By following the best practices for connection management, you can appropriately scale the database cluster, lower costs, and improve performance. You have two choices with Aurora Serverless: manage your own application connection pooling or use the Amazon RDS Data API.
Application connection pooling
Connection pooling is a good solution for some applications, such as long-running programs, applications that don’t need scale the application layer, and applications with steady traffic. Connection pooling reduces the number of times new connections are opened with the database. When you need a new connection, you get an already established connection from the pool. When the application closes the connection, the connection is returned to the pool instead of being closed. Connection pooling can enhance your application’s performance and scalability because it reduces the number of times new connections are created and it quickens the process of getting a connection. It also avoids unnecessarily keeping the database cluster at a higher capacity because you maintain only as many connections as you need. Lastly, connections in the pool are automatically closed if they aren’t used for a certain time.
If connection pooling suits your use case, make sure you follow general best practices:
- Ensure appropriate timeouts and health checks
- Retrieve a connection from the pool as late as possible and return it as soon as possible
- Always close a connection, including in the event of an exception
Connecting to an Amazon Serverless DB cluster
A DNS scan is necessary for the custom implementation of a connection failover. However, the mariadb:aurora parameter avoids the automatic DNS scan for failover targets, thereby eliminating the scanning, which causes a delay in establishing the connection. If you use the MariaDB Connector/J utility with an Aurora Serverless cluster, use the prefix jdbc:mariadb:aurora// in your connection string.
Aurora Serverless closes connections that are older than 24 hours. Make sure that your connection pool refreshes connections frequently.
Data API
Due to the transient nature of serverless applications, you often have more connections than in traditional applications. Because there’s no persistent server, there’s no place to store a connection identifier for reuse. Managing connections for serverless applications can be cumbersome.
The Data API reduces the effort of managing database connections or connection pools. The Data API doesn’t require a persistent connection to the DB cluster. Instead, it provides a secure HTTP endpoint, backed by a connection pool. The Data API uses database credentials stored in AWS Secrets Manager so you don’t need to pass credentials in the API calls. With the Data API, you can avoid the complexity and overhead that comes with connection management. The following diagram illustrates a representative Aurora Serverless architecture using the Data API.
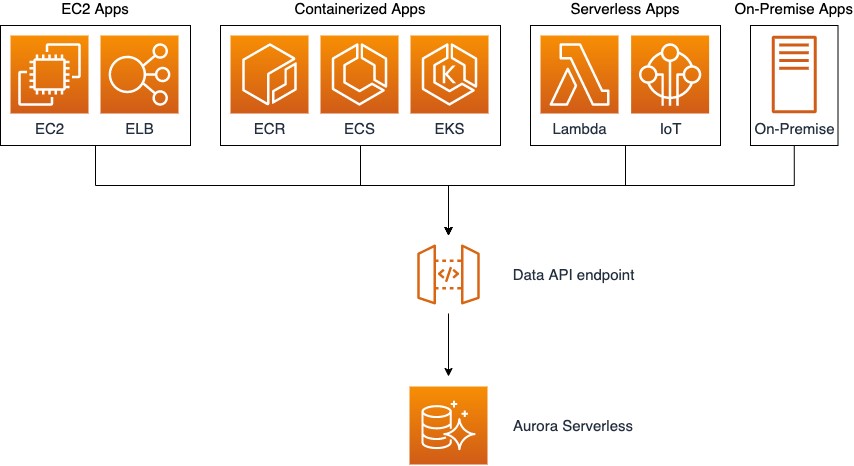
To learn more about the Data API, see Using the Data API for Aurora Serverless.
Minimum capacity
Capacity in Aurora Serverless is measured in Aurora Capacity Units (ACUs). Each ACU comes with approximately 2 GB of memory, corresponding CPU, and networking. As a best practice, set the appropriate minimum capacity instead of using the default value.
Aurora Serverless scales up when capacity constraints are seen in CPU or connections. However, finding a scaling point can take time (see the Scale-blocking operations section). Test your application to determine the proper minimum capacity. If you observe that your application needs more resources, set a higher minimum capacity. If you find your cluster is struggling to find a scaling point, it could be your minimum capacity is too low, and your database is too busy to pause transactions and scale. In that case, set your minimum capacity higher and re-run the test again.
If there is a sudden spike in requests, you can overwhelm the database. Aurora Serverless might not be able to find a scaling point and scale quickly enough due to a shortage of resources. This is especially true when your cluster is at 1 ACU capacity, which corresponds to approximately 2 GB of memory. Typically 1 ACU is not adequate for production workloads.
Minimizing pause and resume time
You can choose to pause your Aurora Serverless DB cluster after a given amount of time with no activity. When the DB cluster is paused, no compute or memory activity occurs, and you’re charged only for storage. If database connections are requested when an Aurora Serverless DB cluster is paused, the DB cluster automatically resumes and services the connection requests.
Some applications may require a fast resume. Resuming the cluster takes a few seconds and in some cases can be longer based on variables such as your ACU, storage size, and more. To avoid a cold start, consider disabling auto pause and, as discussed in the previous section, set the proper minimum capacity.
Pre-warming
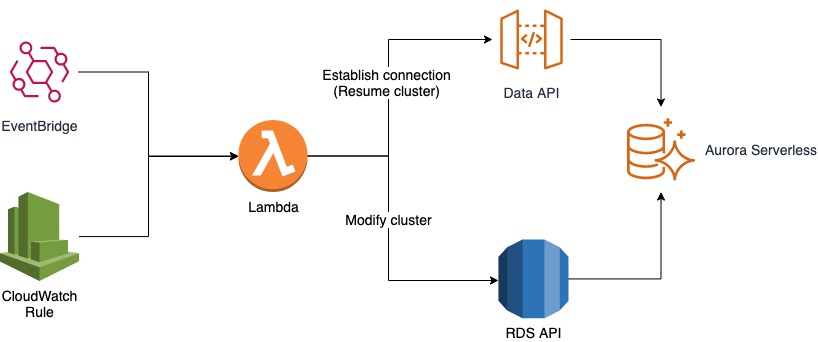
You may have use cases when you know exactly when to scale up or resume the cluster, or use cases when you expect a sharp increase in load in a short period. In those cases, scaling up or waking up might not be quick enough. Instead, you can pre-warm your cluster. You can either resume your cluster by establishing a new connection through the Data API, or you can call the Amazon RDS API to modify the cluster to your needs. To run a periodic job, you can create a scheduled Amazon CloudWatch rule or use Amazon EventBridge to call AWS Lambda to do the job. For instructions, see Tutorial: Schedule AWS Lambda Functions Using CloudWatch Events and Tutorial: Schedule AWS Lambda Functions Using EventBridge, respectively. When resuming a cluster, make sure you run your load within the SecondsUntilAutoPause time frame. The following diagram illustrates this architecture.
One cluster = one database
In the traditional database world, it’s common to have a cluster containing multiple databases. It helps reduce maintenance and cost. That’s not true for Aurora Serverless. AWS performs maintenance and updates automatically. There’s no limit to the number of databases you can have in an Aurora Serverless cluster, but it’s a best practice to only group schemas or databases that serve similar application use cases. Splitting up unrelated databases across separate clusters reduces the blast radius of potential failures or performance issues, and scaling operations can run independently based on the unique database traffic patterns. Unlike other database engines, there is no cost benefit by consolidating multiple databases into a single cluster as long as you set the right capacity settings. Because the main cost for Aurora Serverless is per ACU (not per cluster or any license), you can also achieve cost savings in the long term.
Scale-blocking operations
The capacity allocated to your Aurora Serverless DB cluster seamlessly scales. But using long-running queries or transactions and temporary tables or table locks can delay finding a scaling point.
Long-running queries or transactions
For transactions, you should follow standard best practices. For example, keep your transactions simple, short and use a suitable isolation level. For more information, see Transactional and Locking Statements and Optimizing InnoDB Transaction Management.
The most important practice is to avoid long-running transactions. In general, for any relational database, long-running transactions can cause performance degradation. Specifically for Aurora Serverless, long-running transactions are blocking operations for scaling unless you use the force scaling parameter. Even in this scenario, you must complete a proper rollback first, which can take significant time. This can have a very negative impact on your application. In any case, you should remember to properly handle rollback exceptions on your application level.
For Aurora Serverless MySQL 5.6, the exception will look as follows:
For Aurora Serverless MySQL 5.7, the exception will look as follows:
If your system requires long-running transactions, first narrow the scope of the transaction to a minimum by accessing the least amount of data inside the transaction body. Try breaking down the transaction into smaller sub-transactions and run them independently. For example, retrieve the data from the tables separately, if possible.
A single long-running query can block scaling. A single query is implicitly a single-statement transaction, therefore they follow similar principles and best practices as mentioned previously for long-running transactions.
Lastly, set proper timeouts for statements and transactions. For PostgreSQL 10, you can use statement_timeout and idle_in_transaction_session_timeout. For MySQL 5.7, use max_execution_time.
Temporary tables or table locks
During your application and database design, remember that temporary tables and table locks are also blocking operations for scaling unless you enable the force scaling parameter. Potential timeout and force scaling results again in a proper transaction rollback. If you use either of those, consider the potential impact on your application side.
A temporary table is a special type of table that allows you to store a temporary result set that you can reuse several times. Aurora Serverless removes the temporary table automatically when the session ends or the connection ends. You can also drop the table manually to remove a temporary table explicitly when you no longer need it. If you have to use temporary tables, try to limit their overall lifetime. Create a temporary table when you need it and drop it as soon as you can rather than wait for automatic cleanup. In some use cases, a temporary table is created internally as part of the statement. Users have no control over when this occurs. The lifetime of these temporary tables is the span of the query itself. Such examples might be UNION statements, views, derived tables, or CTE (common table expressions). For more information, see Internal Temporary Table Use in MySQL.
A similar rule also applies to table locks. Table locks are typically used to emulate transactions or to get more speed when updating tables. If the session ends, either normally or abnormally, Aurora Serverless releases all the locks implicitly. The best option is to avoid table locks. If you must use it, hold the lock for the minimum necessary time.
Retry logic
Numerous components on a network, such as DNS servers, switches, load balancers, and others, can generate errors anywhere in the life of a given request. Other errors include the temporary unavailability of a service or timeouts that occur when a service is busy. These errors are typically self-correcting. The usual technique for dealing with these error responses is to implement retries in the client application. This technique increases the reliability of the application and reduces operational costs for the developer. When you design your application, make sure that you implement retry logic in your data access layer. For more information, see Exponential Backoff And Jitter and Timeouts, retries, and backoff with jitter.
When forced scaling is enabled, the scaling happens as soon as the timeout is reached, which is 300 seconds by default. This behavior may cause a database interruption from your application. If you implement the retry logic, this is handled and retried on your database layer and doesn’t affect the rest of the application. In fact, this can potentially speed up the scaling process and your application can be more resilient.
Difference between Aurora Serverless PostgreSQL and Aurora Serverless MySQL
Aurora PostgreSQL and Aurora MySQL are two different database engines, but in terms of Aurora Serverless, both Aurora Serverless PostgreSQL and Aurora Serverless MySQL have no major differences. There are slight differences in the availability of ACU configurations and, consequently, specific server compute and memory configuration. The most important difference is that Aurora Serverless MySQL supports a minimum ACU configuration of 1 and Aurora Serverless PostgreSQL supports a minimum of 2.
Accessing Aurora Serverless
Aurora Serverless resides in the private subnet of Amazon Virtual Private Cloud (Amazon VPC). You can’t give an Aurora Serverless DB cluster a public IP address; you can only access it from within a VPC based on the Amazon VPC service. You can use any service, such as Amazon Elastic Compute Cloud (Amazon EC2), Lambda, Amazon Elastic Container Service (Amazon ECS), and more, if they reside within the same VPC.
For developer access to the Aurora Serverless cluster, you have two kinds of access: the Data API or an SSH tunnel through a jump box.
Data API access
For the following options, you must enable the Data API for your Aurora Serverless DB cluster.
For easy and basic access, you can use the Query Editor for Aurora Serverless on the Amazon Relational Database Service (Amazon RDS) console. Query results are instantly visible on the console. The Query Editor is suitable for verifying the contents of the table or performing some quick SQL statements.
You may prefer to use the AWS Command Line Interface (AWS CLI) directly, which Aurora Serverless supports.
The following code is an example for Linux, macOS, or Unix:
The following code is an example for Windows:
Similarly, you can use the Data API to easily connect and run any SQL statement against the database with a simple Lambda function. The function doesn’t need to be inside a custom Amazon VPC or have any MySQL or PostgreSQL drivers. You just make SQL statements as an HTTP request.i
SSH tunnel access
The other option is using AWS Cloud9. AWS Cloud9 is a cloud-based integrated development environment (IDE), which provides terminal access with just a browser. The main advantage is you don’t need to install or maintain a local IDE. For instructions, see Configure and Connect to Serverless MySQL Database.
You might already be familiar with some IDEs, such as MySQL Workbench, HeidiSQL, pgAdmin, or DBeaver. You can still use them with a setup similar to that for AWS Cloud9. Because you can’t connect directly to your server over SSH, you must set up a jump box. This is the same as in the AWS Cloud9 configuration, which is done for you automatically. To set up a jump box, complete the following steps:
- Create a Linux-based EC2 instance in the same Region and the same VPC as the Aurora Serverless cluster.
- Make sure you can SSH to the instance using the user name and private key.
- Enable client network access to your cluster:
- Find the VPC security groups for your cluster.
- Choose Inbound Rules.
- Add a new rule with Source as the security group ID of your EC2 instance and Type as one of the following:
- MySQL/Aurora (3306) for MySQL
- PostgreSQL (5432) for PostgreSQL
- Update your IDE:
- For cluster hostname or IP address, use the Aurora Serverless cluster database endpoint.
- For cluster credentials, enter the cluster user name and password.
- For cluster port, enter the following:
- 3306 for MySQL
- 5432 for PostgreSQL
- For SSH host and port, set your public DNS name for your EC2 instance.
- For SSH user name, enter the user name you use to access your EC2 instance.
- For SSH, set your private key (
.pem).
Resilience
Resilience is an important part of the design. Aurora Serverless offers features to help support your data resiliency.
Failover
Aurora separates computation capacity from storage. The storage volume for the cluster is spread across multiple Availability Zones. The durability of the data remains unaffected even if outages affect the DB instance or the associated Availability Zone.
Aurora Serverless clusters are monitored for availability and automatically replaced when problems are detected; you don’t need to intervene on your end. Aurora Serverless manages the warmpool of pre-created DB clusters. The replacement process then fetches a new DB instance from the warmpooling service and replaces the unhealthy host.
The DB instance for an Aurora Serverless DB cluster is created in a single Availability Zone. In the unlikely event that an entire Availability Zone becomes unavailable, Aurora Serverless launches a new instance for your cluster in one of the other Availability Zones. We refer to this capability as automatic Multi-AZ failover. This failover mechanism takes longer for Aurora Serverless than for an Aurora provisioned cluster. The Aurora Serverless Availability Zone failover is done on a best effort basis because it depends on demand and capacity availability in other Availability Zones within the given AWS Region. Because of that Aurora Serverless is not supported by the Aurora Multi-AZ SLA.
Replication
Binlog-based replication and the Aurora Replicas feature are limited for Aurora Serverless DB clusters. If you need these features, consider using the provisioned version of Aurora. For more information, see Limitations of Aurora Serverless.
You can use Aurora Serverless as a target for AWS Database Migration Service (AWS DMS) data replications. For more information, see Getting started with AWS Database Migration Service.
Security
Cloud security at AWS is the highest priority. The following sections show you the recommended configuration of Aurora Serverless to meet your security and compliance objectives. You also learn how to use other AWS services that help you monitor and secure your Aurora Serverless resources.
Patching and maintenance
Aurora Serverless performs regular maintenance so your DB cluster has the latest features, fixes, and security updates. Aurora Serverless performs maintenance in a non-disruptive manner whenever possible. However, it may interrupt your workload in some use cases. For more information, see How Aurora Serverless Works. To avoid any interruptions, we recommend you follow the same best practices as already mentioned in the Scale-blocking operations section.
TLS/SSL
To improve security, you can connect to Aurora Serverless clusters using the Transport Layer Security/Secure Sockets Layer (TLS/SSL) protocol. The use of SSL is recommended and it’s the first choice for establishing a new connection, but it’s not required. To make sure that your session uses TLS, specify the requirement on the client side with the --ssl-mode parameter equal to VERIFY_CA or VERIFY_IDENTITY. Aurora Serverless supports TLS protocol version 1.0, 1.1, and 1.2.
Snapshots
The cluster volume for an Aurora Serverless cluster is always encrypted. You can choose the encryption key, but can’t turn off encryption. To copy or share a snapshot of an Aurora Serverless cluster, you encrypt the snapshot using your own AWS Key Management Service (AWS KMS) key.
Monitoring
Aurora Serverless provides a variety of CloudWatch metrics that you can monitor to determine the health and performance of your Aurora Serverless DB cluster. To access CloudWatch metrics, you can use tools such as the Amazon RDS console, AWS CLI, or CloudWatch API.
In a traditional database scenario, you need to monitor several infrastructure metrics. Because Aurora Serverless is a fully managed service, you don’t need to monitor the health of the underlying infrastructure. Platform and application management and any operating system and network configuration is the responsibility of AWS, but it’s important to remember that customers are responsible for access management, their application, and performance. The shared responsibility model describes responsibilities between AWS and the customer.
Creating a proper monitoring plan is a difficult topic with many variables. For more information about setting up the right monitoring goals, see Monitoring an Amazon Aurora DB Cluster.
Amazon RDS Performance Insights is currently available for use with only some DB engines. For more information, see Using Amazon RDS Performance Insights.
Logs and auditing
You can have Aurora publish some or all database logs to CloudWatch. You can perform real-time analysis of the log data, audit database activity, and use CloudWatch to create alarms and view metrics. You can also store your log records in highly durable storage.
You select which logs to publish by enabling the configuration parameters in the DB cluster parameter group associated with the Serverless cluster. Serverless clusters don’t require you to specify which log types to upload to CloudWatch like provisioned clusters. Serverless clusters automatically upload all available logs. When you disable a log configuration parameter, the publishing of the log to CloudWatch stops. You can also delete the logs in CloudWatch if you no longer need them.
After enabling Aurora Serverless log events, you can monitor the events in CloudWatch Logs. A new log group is automatically created for the Aurora DB cluster under the following prefix, in which my_db_cluster represents the DB cluster name, and log_type represents the log type:
Aurora Serverless PostgreSQL uses a single log type called error.
For Aurora Serverless MySQL, you control logging with the following parameters:
- slow_query_log – Creates a slow query log
- long_query_time – Prevents fast-running queries from being logged in the slow query log
- general_log – Creates the general log
- log_queries_not_using_indexes – Logs all queries that don’t use an index to the slow query log
- server_audit_logging – Enables or disables Advanced Auditing, and the server_audit_events specifies which audit events to log
For more information, see Publishing Amazon Aurora MySQL Logs to Amazon CloudWatch Logs and Using Advanced Auditing with an Amazon Aurora MySQL DB Cluster.
For Aurora Serverless PostgreSQL, you control logging with the following parameters:
- log_statement – Controls which SQL statements are logged
- log_min_duration_statement – Sets the limit in milliseconds of a statement to be logged
- log_connections – Logs all new client connection details; enabled by default and can’t be modified
- log_disconnections – Logs all client disconnections; enabled by default and can’t be modified
- log_temp_files – Controls logging of temporary file names and sizes
- log_lock_waits – Logs sessions that are stuck in a locked state
- log_autovacuum_min_duration – Logs information of autovacuum and autoanalyzer runs (you must enable
rds.force_autovacuum_logging_level) - force_admin_logging_level – Captures the activities from
rdsadminuser
For more information, see Working with RDS and Aurora PostgreSQL logs: Part 1 and Working with RDS and Aurora PostgreSQL logs: Part 2.
Conclusion
This post discussed best practices for Aurora Serverless, which should help you design your architecture and make more robust, secure, and scalable applications. To get started on Aurora Serverless today, see Building serverless applications with Amazon Aurora Serverless.
For more information about Aurora Serverless, see the following:
If you have questions or suggestions, please leave a comment.
About the Author
 Milan Matejka joined Amazon in 2017. He is a Software Development Engineer at Amazon Web Services. Milan holds a master’s degree in Mathematical Analysis.
Milan Matejka joined Amazon in 2017. He is a Software Development Engineer at Amazon Web Services. Milan holds a master’s degree in Mathematical Analysis.
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
United Linux
