
In “Something is (still) rotten in the kingdom of artificial intelligence,” which was about useful-to-know Achilles’s heels of the current second wave of AI, I mentioned that these Achilles’s heels are all of a single making: the fact that our underlying technology is digital or, more correctly, discrete.
Current neural networks, for instance, are just data-driven rule-based systems in disguise (with hidden rules). In the end, a computer is a Turing machine and the fact that I am programming it differently doesn’t change its fundamental capabilities. And these capabilities have limitations, as the kind of intelligence you want is not logical rule-based and can also not be emulated with logical rule-based approaches.
That is why there are scientists all over the world are hard at work at creating computing with a radically different foundation: the operations known as quantum mechanics, the weird behavior that underlies the reality that we experience every day. For instance, the fact that you can rest your hand on a seemingly solid table, while in fact it is mostly made up of nothing, is the result of the Pauli exclusion principle, one of the interesting rules of behavior of nature at the quantum level.
All this scientific work captures the imagination of many, and people may even believe that it will not be long before quantum computing takes over the world. You may find a lot of this on tellingly titled blogs like Next Big Future where for instance in the outlook for 2018-2028 it is simply stated: “Artificial Intelligence and quantum computers will transform IT and logistics.”
Will they? Maybe it is a good idea for another dose of realism. Let’s start with the digital computers that are all-pervasive these days and are the machines that work the current wonders (and Achilles’s heels) of AI.
Digital computing
Digital computers are classical logic machines or, as one of the founders of computing Alan Turing would have it, “discrete state machines,” which are:
Machines which move by sudden jumps or clicks from one quite definite state to another. These states are sufficiently different for the possibility of confusion between them to be ignored. Strictly speaking there, are no such machines. Everything really moves continuously. But there are many kinds of machine which can profitably be thought of as being discrete-state machines. For instance, in considering the switches for a lighting system it is a convenient fiction that each switch must be definitely on or definitely off. There must be intermediate positions, but for most purposes we can forget about them.
Digital computers have many, many states, but all these states are clearly separated from each other, the way characters are separated from each other, there is no overlap, something is either an A or a B; there is no halfway A-B character or a character that is both A and B concurrently. (Incidentally: I sometimes ask people how old they think that digital technology is. They never give what in my view the correct answer is: a few thousand years. Any alphabet is discrete and as such digital). This discreteness is what underlies all our digital technology. Everything in digital technology is based on this foundation. And this foundation, again, is just machinery that can operate what we call classical logic on discrete states. True or false everything is, and nothing else. You could argue that writing is more reliable than oral reports because of the fact that the discreteness of alphabets makes transport reliable over space and time. There is more to that line of thought, but I am digressing as usual. Anyway, digital computers handle only discrete states, they just handle integers using classical logic and nothing else.
You might be forgiven to think that that is not true. After all, won’t computers easily handle real numbers? Can’t you work with numbers like 2.47 and 3.1788835552 in your spreadsheet, and doesn’t the computer handle these perfectly? But dig deep and it turns out that digital computers play a trick on you. They calculate with integers. They fake real numbers with representing them as exponentiation, using integers as a base and integers as an exponent. And they’re so good at it that we tend to assume that they are handling real numbers. But they are not. They may represent a lot of numbers exactly, but not all, which means that whatever the mechanism, you will see rounding errors (some older background here).
There were analog computers before there were digital computers, and they have even somewhat resurged. Where a digital computer has bits that are either 0 or 1 (making it discrete), analog computers have values that can be anything between two values (such as 0 and 1). (Technically, digital computers also have states between 0 and 1; for instance, while they are switching from one to the other, but the digital computer has means (the clock) to ignore values during these intermediary states. As Turing said, physically, digital computers exist because we forget about the states where the situation is between 0 and 1.). But the hope of many is directed not at analog computers but quantum computers, computers using the quantum physics that underlies our reality at the smallest scale.
Quantum computing
Quantum computers as they are envisioned now are a very special kind of digital computer. Instead of each bit begin either 0 or 1 and nothing else, a qubit (the bit in quantum computing) can during operation be 0 and 1 at the same time (a quantum-specific state called superposition). In such a state, each qubit has a probability of being 0 and a probability of being 1, the sum of which is 1. The moment a qubit is measured, it becomes either a 0 or 1. Quantum computing is about not ignoring what happens when the bit is not 0 or 1, in combination with the weird “being two things at the same time” behavior of the smallest scale of our everyday reality.
The intuitive but false story about quantum computing goes like this:
Being in two states at once provides interesting possibilities for parallelism. Suppose you want to guess an eight-bit number, say an encryption key, that is a value of between 0 and 255. In an eight-bit digital computer, you have to try them all one by one. So, you start with the number 0 (eight 0 bits, or 00000000), then if that fails with the number 1 (seven 0 bits and one 1 bit, or 00000001), etc. If the number you have to guess is 255, you have to do your operation 256 times; on average, you have to do it 128 times.
Now, suppose the number to guess such as an encryption key, or the best route of a possible 256 routes for a delivery car to deliver all its packets) is 153, or 10011001 in binary. In a digital eight-bit computer, you have to make 154 tries. But if your computer is a quantum computer, you start with one eight-qubit superposition, or {0 or 1}{0 or 1}{0 or 1}{0 or 1}{0 or 1}{0 or 1}{0 or 1}{0 or 1} and in one step, the computer finds the answer {0 or 1}{0 or 1}{0 or 1}{0 or 1}{0 or 1}{0 or 1}{0 or 1}{0 or 1}. On average, your eight-bit quantum computer will be 128 times as fast as an eight-bit digital computer. In real-world terms, where computers are 64bit, a 64-bit quantum computer will be 263 times as fast, or 4,611,686,018,427,387,904 times as fast in this kind of operation. So, the more bits, the more impressive the gain, because of the massive parallelism that superposition brings. And that is only for one single operation. What if the outcome of the first operation is input for the second operation? The potential is—in theory—almost infinite.
But the story is wrong. There are several huge flies in the ointment.
The true story about quantum computing goes like this (inspired by and sometimes paraphrasing writings by Scott Aaronson; see here, here, here and here).
First, the basics
I am simplifying the story, so it is technically not perfectly correct, but it does give the right idea.
An, at first seemingly small, fly in the ointment is that qubits are very hard to make. Most technologies will have to work at near absolute-zero temperatures. So, making lots of them is a problem. This is called the width of the quantum computer. Scientists can now make roughly 70 qubits working together. The second fly in the ointment is that qubits are fundamentally unstable. You need to work on qubits in isolation, but this isolation cannot be perfect. So, you only have a limited number of quantum operations you can perform before the whole thing crashes. The number of operations you can perform before the thing crashes is called the depth of a quantum computer. And the larger the width, the harder depth becomes. No ones knows if this problem is even solvable. There might be a hard limit around the corner.
To make matters worse, there is also fundamentally a chance to read (measure) a qubit wrong or for quantum operations (the steps in a quantum algorithm) to operate incorrectly, which brings us to another fly: the error rates: Quantum computing is fundamentally uncertain, and outcomes cannot be trusted perfectly. The way to get around this is, for instance, to calculate many times (formally, you need to have something that is more than two thirds of the time correct to do it this way). Another way is to have a digital computer check the result. The latter is, for instance, possible when you are after answers that are hard to find but easy to check, such as an encryption key. So, what you preferably need is not just a quantum computer, but an error-correcting quantum computer. To have enough room for quantum error correction, you need lots and lots of qubits, which brings us back to the first fly.
But these two, potentially even unsolvable, issues are not even the real problem. For the real problem, you need to dive into the actual working of a quantum computer and why the wrong explanation above is actually wrong.
A true part of the “wrong story” is this: While a 64-bit number in a digital computer can have 264, or 18,446,744,073,709,551,616 distinct values, it can only have one such a value at any time. A 64-qubit computer can—while it is calculating—have all these values simultaneously in a single 64-qubit memory. A comparable 64-bit computer would have to have not one single 64-bit number to operate on, but it would have to have 288,230,376,151,711,744 64-bit values to operate on. Simultaneously. That’s a bit like having 288,230,376,151,711,744 CPUs in your computer. With current digital technology, such a computer would weigh more than 11,529,215,046,068 kilograms and use 288,23,037,615,171 megawatts of power. That’s 14 billion times the total average power that humanity currently uses. For a single computer. That’ll definitely put the final nail in the climate coffin.
So, the 64-qubit computer is extremely efficient while it is operating on all the values in parallel. But then comes reading the calculation result, what in a quantum computing is the measurement of the state of those qubits. And then you run into quantum mechanics’ fundamental property: The measurement result is random. In quantum mechanics, individual events cannot be predicted, only statistical averages can. So, when you read a 64-bit quantum computer’s 64-bit value at the end of operation, you get a random number, not necessarily the answer you are looking for.
Here’s why: Suppose we have a qubit that can be in a mixed state of up and down. Each state can be thought of as a wave. The amplitudes of these waves, when squared, give the probability of that state. And these probabilities (the amplitudes squared) add up to 100 percent. At all times, a qubit has a probability for each of its two possible states, all chances together adding up to 1 (or 100 percent). But when you measure it, it randomly (but with a chance given by those squared amplitudes) becomes one of the states. In other words, when the qubit is in a state where it has a up amplitude of 0.3, it has a 0.09 (or 9 percent) chance of becoming up when measured. It thus has a 91 percent (or 0.91) chance of becoming down when measured. And that means the down amplitude is roughly plus or minus 0.95. 0.3 squared is 0.09. Roughly, 0.95 squared is 0.91. Which means that even with a down amplitude of 0.95, measuring it has a 9 percent chance of producing up when it is read. (compare to this: A bit on digital media that physically produces a 95 percent of the amplitude of a 1 bit reads as a 1 with perfect certainty).
So, when you have a 64-qubit quantum computer, you measure the computation result as a pretty random 64-bit digital number, unless your quantum algorithm is such that the probability of reading the wrong answer is zero. The operation of the steps of the algorithm must lead to a state of all those qubits combined, where every qubit that should be 0 for the correct answer must be so with 100 percent certainty and every qubit that should read as 1 for the correct answer must be so with 100 percent certainty: unless your quantum algorithm makes sure all the wrong answers have a zero probability of being the read result, measuring the state of your quantum computing (reading the answer) will likely give you some wrong random result. This is the main reason why the intuitive but false explanation above, and the number 18,446,744,073,709,551,616 is wrong. Your quantum algorithm that is made up of a successive number of quantum operations on those qubits needs to make sure that the chance of reading (measuring) a wrong answer is (almost) zero.
So, what you need is an algorithm that does precisely this: have quantum operations on your qubits such that—because during operation all the wrong states for qubits have canceled out—only a right answer can be measured (almost) deterministically at the end. This is possible because the waves that define the qubit may interfere with each other based on operations on the qubit. These interferences may be destructive (canceling out) or constructive (boosting), just any wave can interfere with another wave. That way, operations on qubit can drive it to either a 0 percent or a 100 percent probability to being measured in a certain state. A qubit interferes with itself and with the operations performed on it. An operation on a qubit, by the way, is something like shooting a laser or a radio wave at it.
And this need to have algorithms that cancel out’wrong answers really limits what you can do with quantum computers, because there are only a few specific problems for which such algorithms exist. One such an algorithm is famous. It is called Shor’s Algorithm and it is a quantum algorithm that can factor integers in reasonable time. Given that much of encryption and thus security assumes that it takes an impossible amount of time to factor very large integers (say, the 1,300 digits of modern-day encryption values), this quantum algorithm has of course spiked a lot of interest. But there are not many others and it is unclear if there will be many.
To drive the message home: a quantum computer is not some sort of superfast general computer. It is a computer for a very limited and specific set of problems, and there are only a very few algorithms that may do something useful. What problems? Which algorithms? Much of that is still up in the air. The most likely use is probably emulation (calculation) of quantum physics itself, as those calculations often stymie digital computers.
Where we are today
I’m ignoring the D-Wave “quantum annealing” system in this story. Mainly because it is pretty much unclear if such a system actually delivers any speedup from true quantum mechanical effects. Researchers so far have come up empty. It is questionable if it is really a quantum computer, even if it might use some quantum mechanical effects. It might be better seen as dedicated hardware (potentially quantum mechanics in nature) to solve a useful but very limited type of calculation. On me, but I’m no expert, with its optimum-seeking behavior it evokes more the image of an analog computer.
So, where do we stand in terms of actual real quantum computing? Well, in 2011 Shor’s Algorithm has been able to factor 21 into 3*7 using 2 qubits. Wow, Bob, wow. With a mechanism that is better than Shor’s Algorithm, a four-qubit quantum computer has been able to factor the number 143 (11*13). Later researchers proved that that algorithm could actually factor larger numbers as long as those factors only differed in two bits (what researchers then called “a special class of numbers”). 56,153 was in 2014 the largest number factored, though with another quantum computing technology than the one used for Shor’s. We’re still really far from factoring today’s 1,300-digit numbers at the root of encryption in reasonable time.
IBM recently published research that there is a class of problems for which you do not need as much depth (number of steps) on a quantum computer as you need for the same problem on a digital computer. This has widely been reported on the net as “IBM proves a quantum computing advantage over digital computing” and you may walk away with the idea that quantum computing is around the corner. But in fact, what IBM has found is—again—a small set of problems that may not require as much depth (number of steps) on quantum computing as it does on digital computing. Yes, fewer steps are an advantage. But small set (of what already is a small set) is a definitive disadvantage. And is there actually a problem in that set that has a practical application? We don’t know. Maybe. If we are lucky.
Most of quantum algorithms still run on simulations of actual quantum computing hardware, simulations that run on digital computers that do not have the actual capability of truly simulating the underlying hardware because of digital’s limitations with respect to both quantum’s superpositions (so the simulations are slow) as well as with respect to the actual real math that is required to model the underlying physics.
And what about actual quantum computing hardware? Well, Google is testing a 72-qubit quantum processor with a 1 percent readout error rate, and it hopes to be able to keep it coherent for long enough to get over 40 steps from it (depth). That may get Google quantum computing that for a very specific type of problem would outperform a digital computer for the first time. Sounds, great, doesn’t it?
Not so fast. Have a look at the following image from Google’s AI blog:
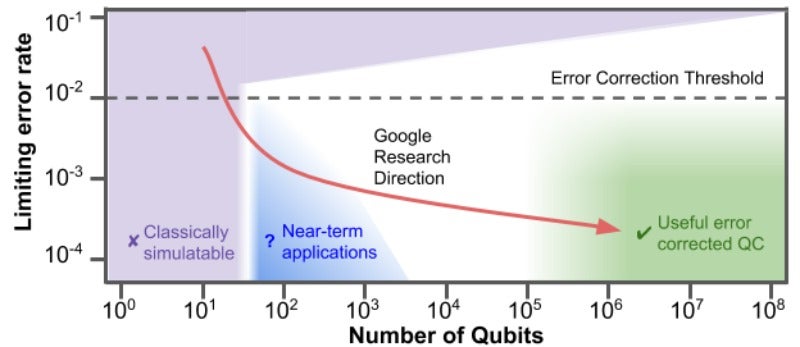
The green area is where the actual useful error-corrected quantum computing is. We need about 100,000 as many qubits per processor and in a coherent state for an extended time period for algorithms to have some depth. You need one to two orders of improvement on the error rate. The blue area might be in reach, however, so some very specific problems may see quantum computing outperform digital computing sooner. Again, the graph is what Google intends, not what it has done. A bit like still not having solved that “labeling dark people as gorillas” problem in three years.
So, not only are what we see now mostly intentions, there are several other hurdles and important notes.
- We may be up against fundamental physical limitations, comparable with the hard limit of light speed.That is, can we overcome decoherence at larger scales? In the words of a 2012 paper: “Is controlling large-scale quantum systems merely really, really hard, or is it ridiculously hard?” and follows up with “In the former case, we might succeed in building large-scale quantum computers after a few decades of very hard work. In the latter case, we might not succeed for centuries, if ever.”
- What kind of problems are actually feasible to calculate using quantum algorithms (and better than digital)? The set is interesting, but also limited. A quantum computer will not be a general-purpose computer; it will have specific advantages for specific mathematical problems. From that same article on one such class of problems: “It seems that … speedups are possible only for problems with special structure well matched to the power of a quantum computer.” In fact, what quantum computers may be best at is doing calculations about quantum physics. A bit like the analog computers that were electronic analogs for mechanical problems (such as target calculation for large guns), and definitely not what is in the mind of hype-peddlers.
- There are the problems where you cannot check correct operation of a quantum computer at all other than running it on another quantum computer or performing a real-world experiment. That kind of sounds like the hidden-proxy problem of my previous article. Yes, the answer is 42, but we have no idea what it means.
- The necessity of error correction is one of those areas where we quickly descend into the edge of knowledge or even unknown physics. To create states that both show quantum coherence and stability, theorists dive into worlds of two-dimensional quasiparticles or even worlds with four spatial dimensions. Um.
- And even without that, assumptions that have been made based on approximating mathematical models (physicists almost always have to throw out “negligible” terms or they can’t calculate anything at all) may not hold in reality where these “negligible” terms interact and are not independent. This may have detrimental effects on the possibility of real quantum error correction. Things may be much harder in reality than approximate calculations so far have shown (from a January 2019 article by some very smart Finns and Germans). Another example of how using approximations (just like the ones used by digital computers to approximate real numbers) can be fraught with dangers.
As it turns out, some of the open questions require physics that we don’t have yet, and trying to build quantum computing may in a way be seen as an experiment to get at new underlying fundamental physics regarding the reality we are part of, only formulated in a way that large companies such as Microsoft, Google, and IBM are willing to put a lot of money in it. You have to admire the physicists for their capability of getting money for physics. Or maybe it is just that in the end every physical subject (including computing machinery) becomes a physics subject. Or maybe Microsoft is at it again, as it was during the first AI wave: pouring large amounts of money in hopeless endeavors instead of improving their software.
So, before believing statements like “before 2028, quantum computers will transform IT and logistics,” it’s best not to put your hopes too high for that foreseeable time period. I’m not a big fan of trying to predict the future (you’re lying, even if you’re telling the truth) but this is probably going to take decades of hard work and success is far from certain. That statement is pure hype. Really.
This article is published as part of the IDG Contributor Network. Want to Join?
