
Amazon ElastiCache for Redis is a great way to accelerate cloud applications through caching and other use cases such as session storage, leaderboards, and messaging. Developers use Redis to store application data using in-memory data structures like hashes, lists, and sorted sets. This data can be useful downstream for other purposes such as reporting and data analysis. Because Redis stores data in-memory to provide low latency and high throughput, long-term data storage is impractical due to the high cost of RAM. Therefore, it’s ideal to transfer data from Redis to other AWS purpose-built databases such as Amazon DynamoDB or Amazon Aurora MySQL.
In this post, I describe a simple way to transfer data from ElastiCache for Redis clusters to other AWS database services using AWS Lambda functions.
Use case
Developers use the hash data type to represent objects or property bags that can be mapped to a DynamoDB or relational table row, such as a website shopping cart. For our use case, we use Redis to store customer selections, helping provide a fast and interactive experience. When the customer decides to make a purchase, the selected items are sent to the billing system for processing, where they are persisted. One way to enable business analysis is to have a record of the items the customer saved in their cart during their time on the site. You can later use the data to analyze customer purchasing patterns and product selection trends.
Solution requirements
Redis has a rich API that enables efficient reading and writing of data. For example, adding a new field to a Redis hash is as easy as providing a new field name and value with the HSET command. Redis also allows for diverse data structures (strings, hashes, sets, lists), which you can map to different entities in other databases. Therefore, our solution must be:
- Flexible – Because the incoming data can vary so much, we need to call different backends for different data types. For example, we may want to map the data from Redis hashes that include user information to one table and their product preferences to another.
- Scalable – We use Redis to make sure our customer-facing application is highly responsive and can handle fluctuations in traffic. Our solution needs to handle changes in traffic without creating lags or impacting the responsiveness of your Redis-powered front end.
- Reliable – Uptime is critical for retaining the responsive user experience we’re looking for. Our solution needs to allow for redundancy and limit the “blast radius” in cases of failure.
Solution overview
We use several technologies to address our requirements. To keep our solution flexible, we use Lambda functions. You can deploy Lambda functions quickly and easily integrate them with other AWS solutions. To make our data feed scalable, we use Redis keyspace notifications. Keyspace notifications are provided through pub-sub events and can be configured to only emit a subset of commands (for example, only hash-based operations) as well as a subset of keys. With the pub-sub architecture, it’s easy to add nodes that act as subscribers for Redis data changes and scale out the solution so we can handle more incoming traffic.
Redis pub-sub messages are generated in real time and aren’t persisted in Redis. This means messages are lost unless an active client is listening on the right channel. To make a more fault-tolerant version of this solution, you can write data to Redis streams and consume them in a similar manner to pub-sub. Because Lambda doesn’t support the Redis pub-sub trigger type, we use a simple executable hosted on an Amazon Elastic Compute Cloud (Amazon EC2) instance to subscribe to the Redis keyspace notification events and invoke Lambda functions. We don’t cover it in this post, but it’s easy to containerize the subscriber piece and have it scale out with services like Amazon Elastic Container Service (Amazon ECS).
Solution architecture
For our use case, we use two Lambda functions to push data to DynamoDB. A Golang application hosted on an EC2 instance is used as a listener for Redis data changes and to invoke the Lambda functions. The following diagram illustrates the solution data flow and components.
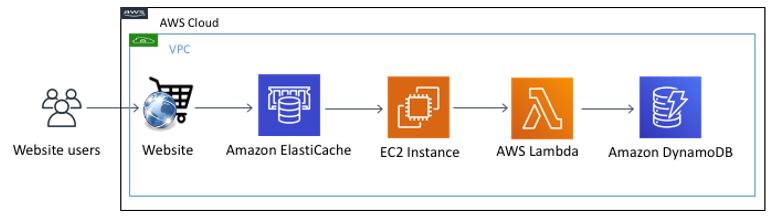
Solution code
The solution contains surprisingly few lines of code, which we discuss further in this section.
Redis listener
The source code for this component is located on the Redis Listener GitHub repo. It’s a Golang executable that uses Redis pub-sub to subscribe to keyspace notifications. We do that by connecting to Redis and subscribing to the appropriate channel.
The PubSubListen() function is called after some initiation work when the Redis listener executable is loaded. See the following code:
LambdaInvoke can be called more than one time for the same Redis hash if you want to send data to more than one destination. The data structure used as an interface between the Redis listener component and the Lambda functions is a very simple JSON object. This iEvent type is shared between the listener component and the Lambda function:
DynamoDB Lambda function
The Lambda function code is also very simple; it takes the iEvent object and sends it to DynamoDB. Because DynamoDB requires a unique ID for each row, we use the name of the hash object from Redis to make sure records are added and updated. Delete is not supported but can be added later on. See the following code:
Our solution includes four different components, as well as security and networking configuration. We use an AWS Serverless Application Model (AWS SAM) template to put it all together.
The template included with this post deploys the DynamoDB table, Lambda function, EC2 instance, and the configuration needed to connect them (VPC, subnets, security group, internet gateway, and route table to allow access to the EC2 instance). When the setup process is complete, you set up the Redis listener component on the EC2 instance.
Prerequisites
AWS SAM makes it easy to create and deploy serverless resources. To get started, you need the following prerequisites on your dev machine:
- The AWS Command Line Interface (AWS CLI) already configured with administrator permission. For instructions, see Installing, updating, and uninstalling the AWS CLI version 2.
- Access to your AWS access key and secret.
- Docker installed.
- Golang
- The AWS SAM CLI installed.
- Git
- Create or make sure you have access to an Amazon EC2 key pair. You use it to connect to your EC2 instance. For instructions on obtaining a key pair, see Creating or importing a key pair.
Deploying your template
When everything is installed, open a terminal window to deploy your AWS SAM template.
- Enter the following code:
The following screenshot shows your output.
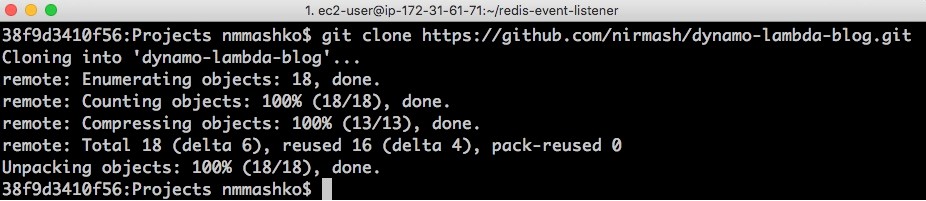
- CD into the new Git folder.
- Enter
SAM build.
The following screenshot shows your output.
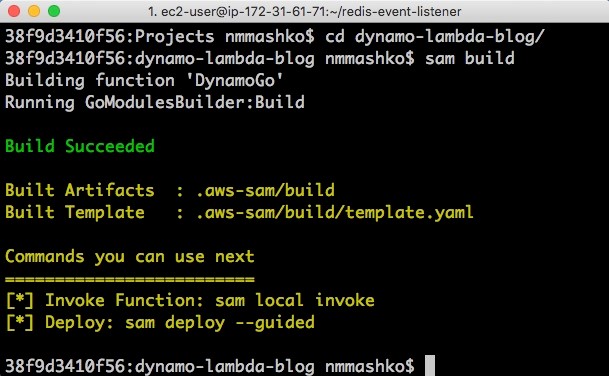
Image: build the SAM template
Now that the template is built, it’s time to deploy.
- Enter
SAM deploy --guided. - Follow the prompts on the screen, using the key pair name you obtained earlier.
- Write down the stack name (first parameter in AWS SAM deploy process) to use later.
The following screenshot shows your output.
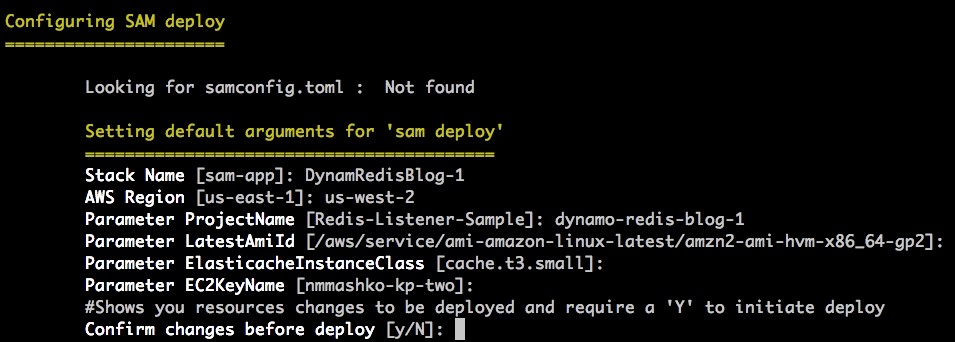
- When the setup process is complete, note the values of the ElastiCache cluster endpoint, ElastiCache instance DNS, and the Lambda function ARN.
You need the name of the DynamoDB table to see the data coming in from your Redis cluster. The following screenshot shows your output.
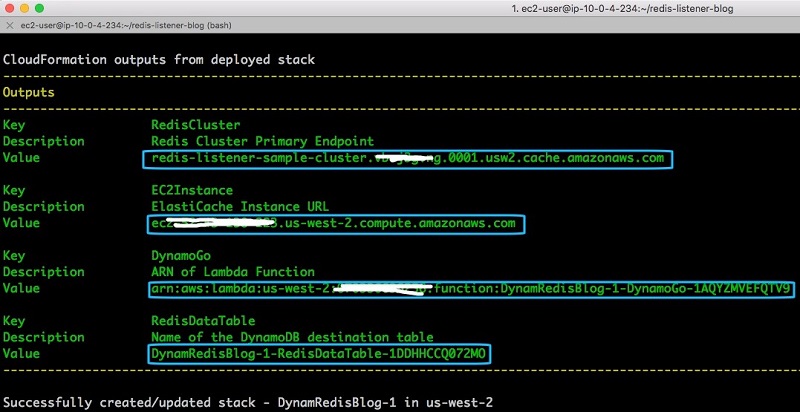
Image: SAM template output
- When your instance is launched, SSH into it.
- To set up the listener service, we need to install a few components on the new EC2 instance:
- Git – In the SSH window, enter
sudo yum install -y git. - Golang – In the SSH window, enter
sudo yum install -y.
- Git – In the SSH window, enter
- Clone the code repository by entering
Now you update the service configuration files to point to the Redis cluster and Lambda function.
- For the environment variables, use an editor to edit the env.sh file in the
redis-listener-blogfolder. Add the following values per instructions:- REDIS_MASTER_HOST – Your Redis cluster primary endpoint
- AWS_ACCESS_KEY_ID – Your AWS access key ID
- AWS_SECRET_ACCESS_KEY – Your AWS secret access key
- AWS_DEFAULT_REGION – The AWS Region where your Lambda function is installed.
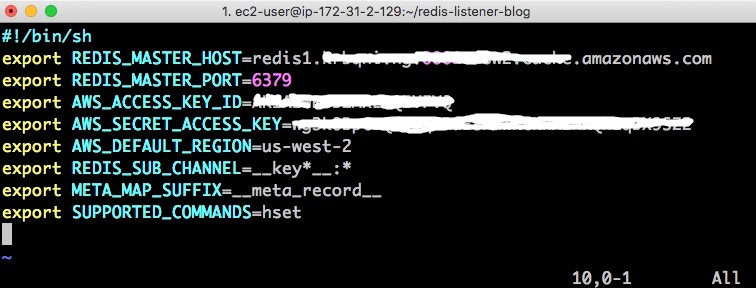
For function mapping, the functionCfg file contains the mapping between Redis keys and the Lambda function. The data from the file is read into a hash key and used every time a new hash field is added or changed to call a Lambda function.
- Replace {lambda_arn} with the ARN of the Lambda function you created.

- Apply the new environment variables from the
source env.shfile by entering source env.sh in the terminal window.
Building and running the service
Now it’s time to build and run the service.
- Enter
go run main.goin the terminal.
The following screenshot shows your output.
You now add data to Redis and see it copied to DynamoDB.
- SSH into your EC2 instance again from a new terminal window.
- Enter
cd redis-listener-blog. - Connect to Redis by entering `
./redis-cli -h <ElastiCache_primary_endpoint_address>`. Provide the Redis primary endpoint you saved earlier.
You should now be connected to Redis.
- Add some hash records to Redis by entering the following code:
The following screenshot shows the output.

- On the DynamoDB console, select the table that starts with
dynamo-go-RedisData.
On the Items tab, you can see the hash records data from Redis.
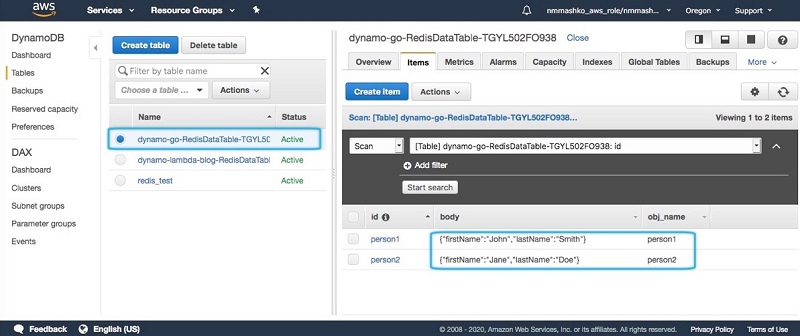
Image: Redis data in DynamoDB
Cleaning up
You now use the AWS CloudFormation CLI to remove the stack:
‘aws cloudformation delete-stack --stack-name <Stack Name you entered earlier>
This call is asynchronous, so don’t be alarmed when it completes immediately. You can check the AWS CloudFormation console for the stack deletion status.
Summary
You can unlock a lot of business value by storing your ElastiCache for Redis data in another AWS data store for long-term analysis or reporting. With AWS, it’s easy to put together a flexible, reliable, and scalable solution that you can extend later to support more destinations for Redis data and more Redis data types.
About the author

Nir Mashkowski is a Principal Product Manager in AWS. Nir has been building software products for the last 25 years and is feeling fortunate to be involved in cloud computing for the last 10.
