
As enterprises grow and data and performance needs increase, purpose-built databases have become the new way to tackle specific data access patterns. Modeling and querying highly connected datasets on a traditional relational database can be performance intensive, and expressing relational-style queries against these datasets can be challenging. Graph databases like Amazon Neptune provide a new means for storing and querying highly connected datasets quickly and at massive scale.
To access the insights in your data using this technology, you first need to model the data as a graph. Often, the data exists across the enterprise in existing relational databases. Converting relational data structures to graph models can be complex and involve constructing and managing custom extract, transform, and load (ETL) pipelines. AWS Database Migration Service (AWS DMS) can manage this process efficiently and repeatably, whether you’re migrating a full application to Neptune or only copying a subset of your relational data for graph-specific use cases.
In this four-part series, we cover how to translate a relational data model to a graph data model using a small dataset containing airports and the air routes that connect them. Part one discusses the source data model and the motivation for moving to a graph model. We discuss this for the labeled property graph in part two and for the Resource Description Framework (RDF) data model in part three. In part four, we show how to use AWS DMS to copy data from a relational database to Neptune for both graph data models.
Setting the stage
Before addressing the mechanics of using AWS DMS to copy data from a relational store to Neptune, it’s important to understand the different data models we use in this post: relational models and graph models.
Relational models
Relational models store data in a tabular format, in which records are stored as rows with a primary key along with other columns containing additional dimensional data. Relationships between tables are modeled via foreign key relationships, in which the first table holds the primary key uniquely identifying the corresponding row in another table. In a relational database application, these relationships are materialized at query time in the form of joins within SQL queries.
Graph models
Graph databases model data as a set of vertices that may be connected to other vertices by edges. Vertices typically represent entities like people, places, and things—or for our use case, airports and countries. You can further describe vertices with attributes. Edges define relationships between vertices, like a route between two airports. As with entities, relationships may have additional details that can be modeled. The technique used to model attributes of relationships is different depending on the type of graph model you use.
Neptune supports two different graph models:
- Labeled property graph – Often referred to simply as a property graph, this model is supported via compatibility with the Apache TinkerPop project and the Gremlin traversal language.
- Resource Description Framework – The World Wide Web Consortium (W3C) recommendation Resource Description Framework model (RDF) is also supported, along with the SPARQL query language.
Although many similarities and overlaps exist in the two graph models, there are differences in the approach to modeling and the mechanics of querying the model after it has been created. Selection of the target graph technology depends on your particular use case and the kinds of questions that you want the model to help you answer.
Property graph model
In a property graph, data is organized as vertices and edges. Each of these have unique IDs and labels, which can be thought of as a type, or class. Vertices model “things” and edges model relationships between those things. Vertices and edges may have properties that further describe them.
You can explore property graphs on Neptune using the Gremlin graph traversal language. Traversals make it easy and efficient to find answers to questions such as:
- What are the air routes from Seattle (SEA) to Wellington (WLG)?
- What is the minimum number of stops needed to get from Seattle (SEA) to Agra (AGR)?
These kinds of questions can be much more difficult to answer using a relational database.
RDF model
In RDF, data is organized as a series of statements in the form of triples. A triple, as the name implies, consists of three parts: a subject, a predicate, and an object—just like a sentence.
We model the subject as an RDF Schema (RDFS) resource represented by a unique identifier called an Internationalized Resource Identifier (IRI). IRIs look very similar to web URLs. Predicates are modeled as RDF properties and are also represented by IRIs. IRIs are often abbreviated with a QName, a shorthand with a standard prefix and local name separated by a colon, such as rdf:type. Unlike the property graph model, a property doesn’t directly hold any attributes. You can use several approaches to model property attributes in an RDF graph. For this post, we show one common option.
RDF graphs are queried using SPARQL. You can use RDF graphs to build knowledge graphs that integrate enterprise data across data silos or use external data such as that found in DBpedia, a knowledge graph built from Wikipedia. You can use SPARQL to find insights and build new graphs on the fly. A knowledge graph using our sample dataset can enable us to:
- Gain insight into a problem space and create new relationships within that space
- Integrate data across sources to build new knowledge and insight
Relational to graph data model translation
In this section, we look at how to map our source relational data to each graph model. Migrating a relational data source to Neptune with AWS DMS has several steps. It’s important first to plan the data models and build the mapping files.
Relational model
In this post, we use a relational database containing airports and the air routes between them as our source data. In non-technical terms, the database contains information like the following:
- Wellington International Airport is located in New Zealand
- Wellington International Airport has the IATA location identifier WLG
- New Zealand has the two-character ISO 3166-1 country code NZ
- The route from Los Angeles International Airport to Auckland International Airport has a distance of 6,512 miles
The following entity relationship diagram shows the six tables that comprise the complete source relational database.
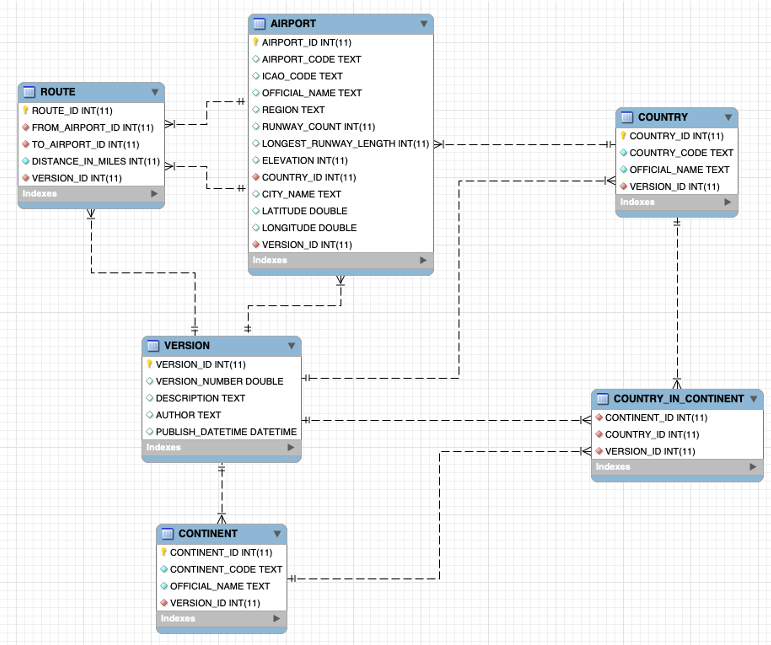
For this use case, we migrate a subset of our tables to our graph. We show how to select the data that we use later. We can streamline the migration process by specifying only the tables and columns that we need. The three tables we use are COUNTRY, AIRPORT, and ROUTE.
COUNTRY
Each row of the COUNTRY table holds the data for a single country. It contains columns with a two-character country code and the official name of the country in English.
| COUNTRY_ID | OFFICIAL_NAME | COUNTRY_CODE |
| 3510 | Australia | AU |
| 3596 | India | IN |
| 3656 | New Zealand | NZ |
| 3723 | United States | US |
AIRPORT
Each row of the AIRPORT table holds the data for a single, unique airport entry. It contains several columns, including a unique key, the airport’s official name, its IATA airport code, and a foreign key linking to the country where the airport is located.
| AIRPORT_ID | OFFICIAL_NAME | COUNTRY_ID | AIRPORT_CODE |
| 12 | New York John F. Kennedy International Airport | 3723 | JFK |
| 13 | Los Angeles International Airport | 3723 | LAX |
| 22 | Seattle-Tacoma | 3723 | SEA |
| 63 | Auckland International Airport | 3656 | AKL |
| 65 | Wellington International Airport | 3656 | WLG |
| 69 | Mumbai, Chhatrapati Shivaji International Airport | 3596 | BOM |
| 654 | Agra Airport | 3596 | AGR |
ROUTE
The final table in our relational database is a little different. It’s more like a junction table, holding the origin and destination foreign keys to the AIRPORT table that define an airport-to-airport route together with the route length.
| FROM_AIRPORT_ID | TO_AIRPORT_ID | DISTANCE_IN_MILES |
| 22 | 13 | 954 |
| 13 | 55 | 7489 |
| 13 | 57 | 7922 |
| 13 | 63 | 6512 |
| 55 | 65 | 1383 |
| 57 | 65 | 1608 |
| 63 | 65 | 298 |
Summary
This series of posts discusses how to translate a relational data model to a graph data model. In this post, we discussed the motivation for moving to a graph model and the tables in our model. In part two, we use these three tables to explore relational to property graph modeling.
If you have any questions, comments, or other feedback, share your thoughts on the Amazon Neptune Discussion Forums.
About the author
 Chris Smith is a Principal Solutions Architect on the AWS Database Services Organization Customer Advisory Team focusing on Neptune. He works with customers to solve business problems using Amazon graph technologies. Semantic modeling, knowledge representation, and NLP are subjects of particular interest.
Chris Smith is a Principal Solutions Architect on the AWS Database Services Organization Customer Advisory Team focusing on Neptune. He works with customers to solve business problems using Amazon graph technologies. Semantic modeling, knowledge representation, and NLP are subjects of particular interest.
