It’s Murphy’s Law of Data: The data you have isn’t always in the format that you need. And not all problems have to do with mistakes or gaps in the data. Sometimes you’ve got wide data that needs to be long; or long data that needs to be wide.
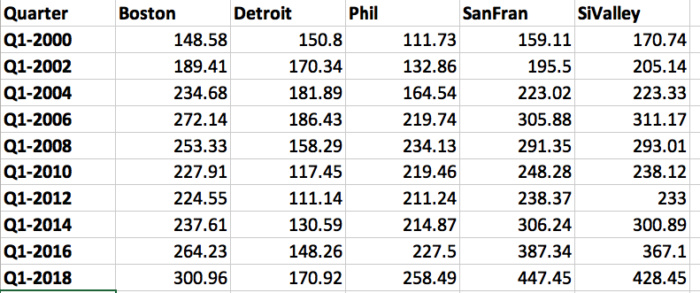
Let’s work on an example. Here, I’ll read in a spreadsheet of home prices in 5 U.S. metro areas: Boston, Detroit, Philadelphia, San Francisco, and San Jose (which I’m calling Silicon Valley). More specifically, data about home prices every two years, when all cities started with an index of 100 in 1995. This data runs from 2000 to 2018.
Here’s a look at the spreadsheet:
IDG
Excel spreadsheet with data in wide format
I import this data using housing_data <- rio::import("housingPrices.xlsx"). If you’d like to follow along without having the spreadsheet, the code to create this data frame is at the bottom of this article.
This is a pretty human-friendly format. It’s sometimes referred to as a “wide” format. Each metro area has its own column, and you can scan down each column and see the movement for that metro area.
But if you want to graph that with ggplot2, you want the data in so-called tidy, or “long,” format. There’s one observation per row, and no data in column names. So you can easily tell ggplot2 color by city. Right now, the city information is in column names not the data itself.
Another example: If I want to calculate which city had the highest index value in each year, it’s pretty easy to calculate which number is highest in each row. But if you want to show which metro area had the highest index value, you have to pull information from the column name.
Here’s what a tidy version of this data looks like.
 IDG
IDG
Spreadsheet with data in a tidy, or long, format
One observation per row: The quarter, the home-price index value, and the Metro area. Not as easy for a person to scan, but much better for analyzing in R—especially with tidyverse packages.
So, if the only version of your data was the wide version, how do you get the long version? One way is with the tidyr package’s gather function.
gather() takes at least three arguments: First is the name of your data frame. Second is the name you want for your new category column—that’s called the key. And third is the name you want for your new value column, that’s called the value. After that are any columns that you want “gathered” into the new key and value columns. If you don’t supply any column names, all the columns get gathered. In this case, we want all the city columns gathered but not the Quarter column. I can exclude that with -Quarter.
This code creates a long or tidy version of the data:
library(tidyr)
housing_data_tidy <- gather(data = housing_data,
key = MetroArea, value = IndexValue, -Quarter)
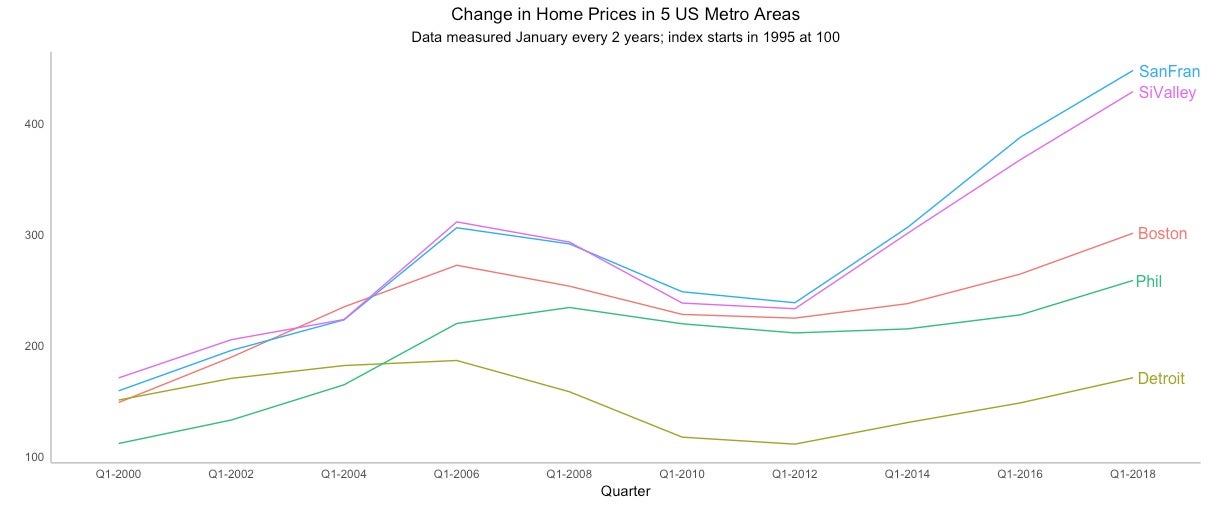
This version is much easier to graph with ggplot2. Just by adding group = MetroArea, my chart plots each metro area as its own series, or line. color = MetroArea gives each line a different color.
library(ggplot2)
ggplot(housing_data_tidy) +
geom_line(aes(x = Quarter, y = IndexValue,
group = MetroArea, color = MetroArea))
The following code adds a little more customization to the plot:
ggplot(housing_data_tidy) +
geom_line(aes(x = Quarter, y = IndexValue,
group = MetroArea, color = MetroArea)) +
theme_minimal() +
theme(panel.border = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
axis.line = element_line(colour = "gray")) +
ylab("") +
ggtitle("Change in Home Prices in 5 US Metro Areas",
subtitle = "Data measured January every 2 years;
index starts in 1995 at 100") +
theme(plot.title = element_text(hjust = 0.5), plot.subtitle = element_text(hjust = 0.5))
I’ve selected a different theme, and then tweaked that by removing all the background grids and y-axis label, adding a title and subtitle, and centering the title and subtitle. Before I go back to reshaping, I’d like to show you a cool package that works with ggplot2 called directlabels.
Here, I’m using the same customized plot I just made, but storing it in a variable called my_customized_plot. Then I run the direct.label() function on it, with the argument last.points and a slight horizontal justification of the text.
library("directlabels")
my_customized_plot <- ggplot(housing_data_tidy) +
geom_line(aes(x = Quarter, y = IndexValue,
group = MetroArea, color = MetroArea)) +
theme_minimal() +
theme(panel.border = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
axis.line = element_line(colour = "gray")) +
ylab("") +
ggtitle("Change in Home Prices in 5 US Metro Areas",
subtitle = "Data measured January every 2 years;
index starts in 1995 at 100") +
theme(plot.title = element_text(hjust = 0.5),
plot.subtitle = element_text(hjust = 0.5))
direct.label(my_customized_plot, list(last.points, hjust = -0.1))
Here’s what happens:
 IDG
IDG
ggplot2 line chart with the directlabels package
Instead of a legend, I’ve got a nice label for each line! I do love that as an option for some plots.
Back to reshaping.
Let’s say I started off with this as tidy data, but wanted to make it “wide” to create a table that’s easier to read. Basically going from the long data frame I have now to that first version I showed with each metro area in its own column. For that, you need the opposite of gather(), which is spread().
spread() also takes data, key, and value as arguments. In this case, the data is your tidy data frame. Key is the name of the existing column where you want the values each turned into their own columns. For this data, it’s MetroArea. We have one column with metro areas, and I want each metro area to be in its own column. Value is the name of the existing column that holds the values that should be spread out into the new columns. R may not know for sure whether that should be the Index column or the Quarter column unless you tell it.
Here’s the code:
housing_data_wide <- spread(housing_data_tidy,
key = MetroArea, value = IndexValue)
And now we’re back to wide data.
The code to create the initial data frame
housing_data <- data.frame(stringsAsFactors=FALSE,
Quarter = c("Q1-2000", "Q1-2002", "Q1-2004", "Q1-2006", "Q1-2008",
"Q1-2010", "Q1-2012", "Q1-2014", "Q1-2016", "Q1-2018"),
Boston = c(148.58, 189.41, 234.68, 272.14, 253.33, 227.91, 224.55,
237.61, 264.23, 300.96),
Detroit = c(150.8, 170.34, 181.89, 186.43, 158.29, 117.45, 111.14, 130.59,
148.26, 170.92),
Phil = c(111.73, 132.86, 164.54, 219.74, 234.13, 219.46, 211.24,
214.87, 227.5, 258.49),
SanFran = c(159.11, 195.5, 223.02, 305.88, 291.35, 248.28, 238.37, 306.24,
387.34, 447.45),
SiValley = c(170.74, 205.14, 223.33, 311.17, 293.01, 238.12, 233, 300.89,
367.1, 428.45))
